The era of “run a model and hope for the best” is over. As generative and agentic AI move from experimental labs to massive data center clusters, the industry has hit a wall: inference at scale is incredibly complex and expensive. Recognizing this bottleneck, NVIDIA has officially entered production with NVIDIA Dynamo 1.0, a software layer they are calling the world’s first “operating system” for AI factories.
Just as a traditional OS coordinates hardware and applications on a single PC, NVIDIA Dynamo 1.0 orchestrates thousands of GPUs and memory resources across a cluster. This launch marks a fundamental shift in how we deploy AI, promising to lower token costs, increase revenue opportunities, and supercharge the performance of the latest Blackwell GPUs by up to 7x.
In this deep dive, we’ll explore how NVIDIA Dynamo 1.0 works, why it is essential for the future of agentic AI, and how you can leverage this open-source foundation to scale your own AI infrastructure.
What is NVIDIA Dynamo 1.0?
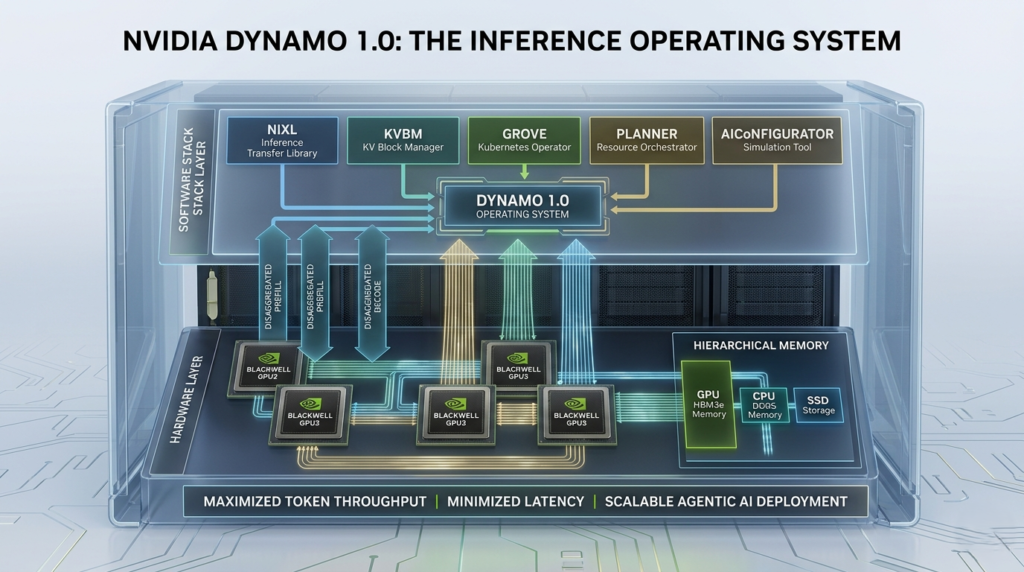
NVIDIA Dynamo 1.0 is an open-source, production-grade inference operating system designed specifically for the distributed environments of modern AI factories. While hardware often steals the headlines, the software that manages that hardware determines the actual “ROI” of an AI deployment.
The primary goal of NVIDIA Dynamo 1.0 is to maximize token throughput while minimizing the cost per million tokens. It achieves this by disaggregating the different phases of AI inference and intelligently routing data across the network to ensure no GPU cycle is wasted.
Key Performance Benchmarks
- 7x Performance Boost: On NVIDIA Blackwell GPUs compared to previous software stacks.
- 30x Throughput Increase: For complex Mixture-of-Experts (MoE) models like DeepSeek-R1.
- Massive Scalability: Designed to orchestrate millions of GPUs across global cloud providers like AWS, Azure, and Google Cloud.
How NVIDIA Dynamo 1.0 Solves the “Inference Problem”
Traditional inference engines often struggle with “stranded” resources—where a GPU is waiting for data or is bottlenecked by memory. NVIDIA Dynamo 1.0 introduces several core technologies to eliminate these inefficiencies.
1. Disaggregated Prefill and Decode
In Large Language Models (LLMs), the “prefill” phase (understanding the prompt) and the “decode” phase (generating the answer) have very different compute requirements. NVIDIA Dynamo 1.0 splits these tasks across different GPU pools. This allows each phase to be optimized independently, preventing the faster generation phase from being held up by slow input processing.
2. KV-Aware Smart Routing
Every time an AI “thinks,” it creates a Key-Value (KV) cache—essentially its short-term memory of the conversation. NVIDIA Dynamo 1.0 includes a KV-cache-aware router that identifies which GPUs already hold the relevant context for a specific user. Instead of recomputing the prompt, the system routes the request to the GPU that already “remembers” the conversation, slashing latency.
3. Hierarchical Memory Management (KVBM)
Memory is the most expensive resource in AI. The KV Block Manager (KVBM) in NVIDIA Dynamo 1.0 treats GPU memory, CPU memory, and even SSD storage as a single, fluid hierarchy. It automatically offloads inactive context to cheaper storage and brings it back instantly when needed, allowing for nearly infinite context lengths without crashing the system.
Core Components: The Building Blocks of Dynamo
NVIDIA has modularized NVIDIA Dynamo 1.0, allowing developers to use the full suite or pick specific “Lego bricks” for their existing stacks.
| Component | Function | Primary Benefit |
| NIXL | Inference Transfer Library | Accelerates GPU-to-GPU data movement. |
| KVBM | KV Block Manager | Optimizes memory usage across storage tiers. |
| Grove | Kubernetes Operator | Simplifies deployment on K8s clusters. |
| Planner | Resource Orchestrator | Dynamically scales GPU pools based on demand. |
| AIConfigurator | Simulation Tool | Finds the best configuration without wasting GPU hours. |
Powering the Next Wave: Agentic AI
The most significant impact of NVIDIA Dynamo 1.0 will be felt in the realm of Agentic AI. Unlike a simple chatbot that answers a single question, AI agents reason, plan, and interact with other AIs. This requires “test-time scaling,” where the model thinks longer to provide a better answer.
NVIDIA Dynamo 1.0 provides the high-concurrency, low-latency foundation required for these agents to function. By integrating natively with frameworks like LangChain, vLLM, and SGLang, it ensures that the “engine of intelligence” can keep up with the rapid-fire demands of autonomous agents.
Implementation: Getting Started with NVIDIA Dynamo 1.0
Because NVIDIA Dynamo 1.0 is open-source, it is highly accessible to developers. It is compatible with NVIDIA GPUs going back to the Ampere architecture (A100s), though it is optimized for the H100 and Blackwell series.
Seamless Ecosystem Integration
NVIDIA is not trying to replace the tools you already use. Instead, NVIDIA Dynamo 1.0 integrates into the most popular open-source frameworks:
- vLLM and SGLang: Native support for high-throughput serving.
- TensorRT-LLM: Deeply integrated kernels for maximum hardware acceleration.
- Kubernetes: Through the “Grove” module for enterprise-grade orchestration.
Actionable Insights for Enterprises
For CTOs and Infrastructure Leads, NVIDIA Dynamo 1.0 represents a clear path to reducing OpEx. Here is how to approach adoption:
- Audit Your Utilization: Use the Dynamo Planner to see where your current GPU fleet is underutilized.
- Enable Disaggregation: If you are running long-context applications, splitting prefill and decode can instantly improve your “Time to First Token” (TTFT).
- Leverage Managed Services: If managing a raw codebase is too complex, providers like Gcore already offer “one-click” managed versions of NVIDIA Dynamo 1.0.
Final Thoughts: The Future of the AI Factory
As Jensen Huang noted, “Inference is the engine of intelligence.” Without a robust operating system, that engine can’t reach its full potential. NVIDIA Dynamo 1.0 provides the necessary “traffic control” to move AI from a series of isolated queries to a global web of intelligent agents.
Whether you are a startup building the next generation of AI agents or a global enterprise scaling your LLM infrastructure, NVIDIA Dynamo 1.0 is the production-grade foundation you’ve been waiting for.