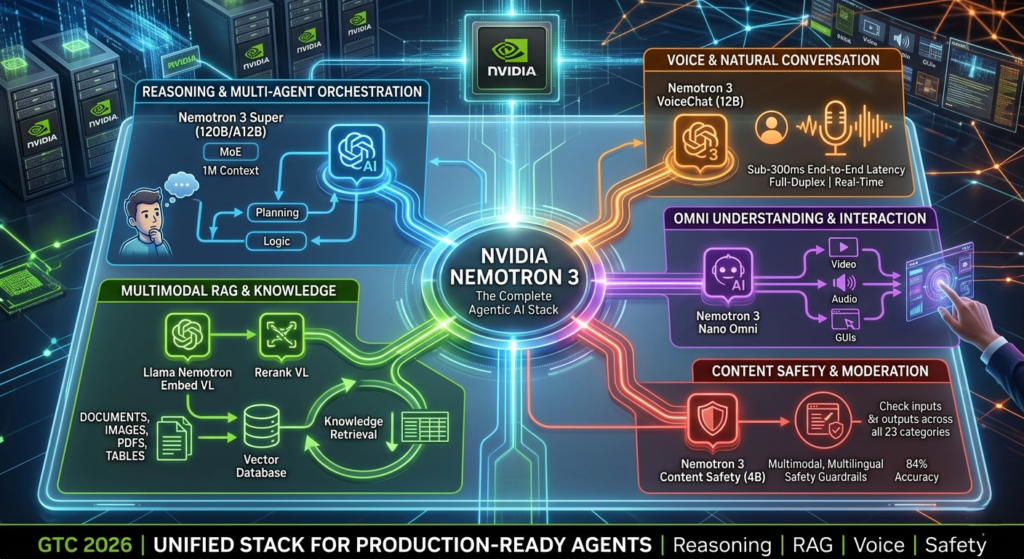
The next frontier of enterprise AI isn’t a single, smarter chatbot. It’s a coordinated system of specialized models that can plan, reason, retrieve information, converse naturally, and stay safe—all at once. That’s the promise of agentic AI, and at GTC 2026, NVIDIA made the boldest move yet toward making it a production reality.
Enter NVIDIA Nemotron 3: a unified family of open, purpose-built models designed to work in concert as a complete agentic stack. Whether you’re building a financial services assistant that processes 100-page PDFs, a healthcare voice agent that handles real-time patient queries, or a cybersecurity platform that autonomously hunts threats, NVIDIA Nemotron 3 provides the building blocks to do it—efficiently, safely, and at scale.
This post breaks down everything developers and AI architects need to know about the Nemotron 3 family, what makes each model exceptional, and how to start deploying them today.(Agentic AI Stack)
Why NVIDIA Nemotron 3 Is a Turning Point for Agentic AI
Most conversations about “agentic AI” are really just about giving a large language model access to a few tools. True agentic systems are fundamentally different: they involve multiple models handling specialized tasks—long-context reasoning, multimodal retrieval, real-time voice interaction, and safety guardrails—all orchestrated together.
NVIDIA Nemotron 3 was designed with this multi-model reality in mind. Rather than one monolithic model trying to do everything, the family assigns each job to a model optimized for it. The result is a stack that is more efficient, more accurate, and more production-viable than any single model could be.
Here’s the full lineup announced at GTC 2026:
| Model | Role | Status |
|---|---|---|
| Nemotron 3 Super (120B/A12B) | Long-context reasoning & multi-agent orchestration | Available |
| Nemotron 3 Ultra | Highest accuracy among open frontier models | Coming soon |
| Nemotron 3 Content Safety (4B) | Multimodal, multilingual safety moderation | Available |
| Nemotron 3 VoiceChat (12B) | Full-duplex, real-time voice conversations | Early access |
| Nemotron 3 Nano Omni | Native omni-understanding (video, audio, docs, GUIs) | Coming soon |
| Llama Nemotron Embed VL (1.7B) | Multimodal RAG embeddings | Available |
| Llama Nemotron Rerank VL (1.7B) | Visual document reranking | Available |
All models are released under NVIDIA’s permissive open model licenses, making them customizable and deployable in security-sensitive enterprise environments.
Nemotron 3 Super: Precision Reasoning at Scale Without Breaking the Bank
The Problem With Multi-Agent Reasoning Today
Agentic systems have two painful hidden costs that most benchmarks don’t measure. The first is context explosion: as agents work through complex tasks, token histories can balloon to 15 times the size of a standard chat session. The second is the thinking tax: chain-of-thought reasoning is triggered on every decision, even low-stakes ones, burning compute and adding latency.
How Nemotron 3 Super Solves This
NVIDIA Nemotron 3 Super is a 120B-parameter open hybrid Mixture-of-Experts (MoE) model—but it only activates 12B parameters per inference pass. That’s the core insight: maximum intelligence, minimum compute per step.
The architecture combines several innovations:
- Hybrid Mamba-Transformer layers — Mamba’s state-space architecture handles long-range dependencies more efficiently than pure attention, which makes it ideal for million-token context windows
- Latent MoE with four specialists — calls four expert sub-networks for the inference cost of one, using token compression before they reach the experts
- Multi-token prediction — generates multiple tokens per step, increasing throughput without sacrificing coherence
- NVFP4 precision on Blackwell GPUs — delivers up to 5x higher throughput than the previous generation while reducing memory footprint
The 1M-token context window isn’t just a number—it means Nemotron 3 Super can hold entire codebases, legal documents, financial reports, or multi-session conversation histories in a single pass. Combined with reinforcement learning across 10+ environments, the model excels at coding, mathematics, instruction following, and function-calling.
A configurable “thinking budget” lets developers cap chain-of-thought length per query, keeping latency and cost predictable even in always-on agent workloads where hundreds of model calls happen per task.
Benchmark Performance
On the Artificial Analysis Intelligence Index for open-weight models under 250B parameters, Nemotron 3 Super NVFP4 ranks among the top tier—matching the highest intelligence scores of competitive alternatives. More importantly, it lands in the “most attractive” upper-right quadrant of the intelligence-versus-efficiency plot, combining top-tier task performance with the highest output throughput per GPU among comparable models.
Best use cases: Software development agents, deep research pipelines, cybersecurity threat analysis, financial services automation, and any application requiring sustained multi-step reasoning at production scale.
Nemotron 3 Content Safety: Safety That Keeps Pace With Your Agent
Safety in Agentic Pipelines Is More Complex Than You Think
When an AI agent is only doing text chat, safety checks are relatively straightforward. But modern agentic systems ingest multimodal data—user-uploaded images, retrieved documents, web content—and produce outputs across text, images, and voice. They operate in high-stakes domains like healthcare (self-harm concerns), enterprise (prompt injection attacks), and social platforms (user-generated content).
Safety guardrails must evolve accordingly.
What Nemotron 3 Content Safety Delivers
NVIDIA Nemotron 3 Content Safety is a compact 4B-parameter multimodal safety model built on the Gemma-3-4B backbone with an adapter-based classification head. It’s designed for one job: high-accuracy safety classification at a latency low enough for inline, real-time moderation in production pipelines.
Key capabilities:
- Multimodal coverage — fuses visual and language features to moderate both text and image inputs
- 12 supported languages — with strong zero-shot generalization beyond them, making it viable for global deployments
- 23-category taxonomy — the same categories used by NVIDIA’s Aegis 1–3 models, covering hate speech, harassment, violence, sexual content, plagiarism, unauthorized advice, and more
- Binary + granular modes — a keyword toggle lets developers choose fast binary (safe/unsafe) classification or full taxonomy reporting depending on the use case
- ~84% accuracy — outperforms alternative safety models across multimodal, multilingual benchmarks
Crucially, the model was trained on high-quality Aegis datasets and human-annotated real-world images, not primarily synthetic data. This makes a meaningful difference in handling edge cases that purely synthetic training often misses.(Enterprise AI Orchestration)
Where It Fits in Your Pipeline
Content Safety can be deployed at multiple checkpoints in an agentic system: moderating user inputs before they reach the reasoning model, screening retrieved content from RAG pipelines before it’s included in context, and validating model outputs before delivery. This “wrap-around” deployment pattern is what separates genuinely safe agents from systems that just have a disclaimer in the footer.
Nemotron 3 VoiceChat: Real-Time Conversation Without the Plumbing
The Hidden Complexity of Cascaded Voice AI
Traditional voice-enabled AI stacks three models in sequence: an automatic speech recognition (ASR) model transcribes audio to text, an LLM processes the text, and a text-to-speech (TTS) model converts the response back to audio. Each handoff adds latency, creates new failure points, and multiplies the operational complexity of deployment.
The result: voice agents that feel slow, robotic, and fragile.
The End-to-End Approach
NVIDIA Nemotron 3 VoiceChat is a 12B-parameter end-to-end speech model that directly processes audio input and generates audio output within a unified streaming LLM architecture. There is no ASR-LLM-TTS pipeline—just a single model.
Built on the Nemotron Nano v2 LLM backbone with a Nemotron Speech Parakeet encoder and TTS decoder, VoiceChat supports full-duplex conversation—meaning it can listen and speak simultaneously, just like a human would in a phone call. It’s interruptible, responsive, and natural-sounding.
Technical highlights:
- Sub-300ms end-to-end latency target — processes 80ms audio chunks faster than real-time
- Single model, fewer failure points — eliminates multi-model orchestration overhead and technical debt
- Full-duplex architecture — handles turn-taking naturally, without requiring rigid push-to-talk or silence detection
On the Artificial Analysis Speech-to-Speech leaderboard, VoiceChat lands in the upper-right “most attractive” quadrant alongside NVIDIA PersonaPlex—the only models combining high conversational dynamics scores with strong speech reasoning performance. This means the model doesn’t just sound natural; it also stays on task and reasons accurately over what it hears.
VoiceChat is currently in early access, with target industries including healthcare, financial services, telecommunications, gaming, and customer experience platforms.
Nemotron 3 Nano Omni: Giving Agents Eyes, Ears, and Context
The Gap in Today’s Multimodal AI
Agentic systems increasingly encounter data that isn’t just text. Real enterprise workflows involve scanned PDFs, video recordings, audio transcripts, dashboard screenshots, and GUI interactions. Most current solutions are either closed-source or face compliance challenges for regulated industries.
What’s Coming: Native Omni Understanding
NVIDIA Nemotron 3 Nano Omni (coming soon) is positioned as the first open, production-ready native omni-understanding foundation model. The architecture is engineered specifically for the challenges of temporal and spatial reasoning:
- 3D convolution layers (Conv3D) — for efficient handling of temporal-spatial data in video, far more effective than processing video as individual frames
- Efficient Video Sampling (EVS) — identifies and prunes temporally static patches, enabling longer video processing at the same computational cost
- Nemotron Speech Parakeet encoder — integrates audio transcription alongside visual understanding
- NVIDIA’s first GUI-trained system — enables agentic interaction with software interfaces, opening new automation possibilities
Combined with state-of-the-art OCR reasoning and the Nemotron 3 Nano language backbone, Nano Omni is designed to give agents genuine situational awareness across every format enterprise data takes.
Multimodal RAG: Llama Nemotron Embed VL and Rerank VL
Why Text-Only Retrieval Fails in the Enterprise
Retrieval-Augmented Generation (RAG) is the most practical way to keep AI agents grounded in specific, up-to-date knowledge. But enterprise data rarely lives in clean text files. It lives in PDFs with embedded charts, scanned contracts full of tables, and slide decks where the critical insight is in an image—not the caption.
Text-only retrieval misses all of this.
The NVIDIA Solution: Visual Document Retrieval
Llama Nemotron Embed VL (1.7B parameters) and Llama Nemotron Rerank VL (1.7B parameters) are compact multimodal models that bring visual understanding to the RAG pipeline while remaining compatible with standard vector databases.
Llama Nemotron Embed VL converts page images and text into a unified embedding vector. Built on the NVIDIA Eagle vision-language architecture (Llama 3.2 1B backbone + SigLip2 400M vision encoder), it uses contrastive learning for query-document similarity. Support for Matryoshka embeddings means you can trade off retrieval accuracy against storage cost at runtime. Crucially, it enables millisecond-latency search—the embeddings integrate directly into Pinecone, Weaviate, Milvus, or any other standard vector database.
Llama Nemotron Rerank VL is a cross-encoder that scores query-page relevance when retrieved candidates include both text and images. Paired with the embedding model, it forms a two-stage retrieval pipeline that consistently outperforms single-stage approaches on visually complex documents.
On the ViDoRe V3/MTEB Pareto curve—which plots retrieval accuracy versus tokens processed per second on a single H100 GPU—Llama Nemotron Embed VL occupies the Pareto frontier: competitive or better accuracy at higher throughput than both open and commercial alternatives.
Practical impact: Your RAG pipeline stops failing silently on charts, tables, scanned pages, and image-heavy documents. Every piece of enterprise data becomes searchable—not just the parts that happen to contain extractable text.
NVIDIA NeMo: Evaluate, Optimize, and Ship Production Agents
Building strong models is only part of the challenge. Shipping reliable agents at production scale requires tools to measure what’s actually happening—and fix it. NVIDIA NeMo provides two critical components:
NeMo Evaluator
An open-source benchmarking framework with native support for agentic evaluation. Key features:
- Standardized evaluation setups — reproducible benchmarks so you can meaningfully compare model versions, configurations, and fine-tuned checkpoints
- Agentic evaluation support — not just single-turn accuracy, but multi-step task completion, tool-use correctness, and reasoning trace quality
- Consistent conditions — eliminates the variability that makes most informal “vibe check” evaluations unreliable
NeMo Agent Toolkit
An open-source framework for profiling and optimizing agentic systems end-to-end, with a critical differentiator: you don’t have to rewrite your agent to use it. Bring agents built on LangChain, AutoGen, AWS Strands, or any other orchestration framework—the toolkit instruments them without code changes.
What you get:
- Visibility into latency bottlenecks across every model call and tool invocation
- Token cost tracking per sub-task to identify where you’re burning budget unnecessarily
- Orchestration overhead analysis to find unnecessary round-trips and redundant model calls
Together, these tools shift agentic development from intuition-driven iteration to evidence-based optimization.
How to Build a Production Agentic Stack With NVIDIA Nemotron 3
Here’s a practical architecture pattern using the full NVIDIA Nemotron 3 family:
Layer 1 — Reasoning and Planning Deploy Nemotron 3 Super as the central reasoning model. Use its 1M-token context window for complex, multi-step tasks. Configure the thinking budget to balance depth of reasoning against latency requirements for your specific workload.
Layer 2 — Multimodal Knowledge Retrieval Build your RAG pipeline with Llama Nemotron Embed VL for embedding all document types—including image-heavy PDFs and slide decks—into your vector store. Add Llama Nemotron Rerank VL as a second-stage reranker for queries where visual content is likely to be relevant.
Layer 3 — Voice Interface For user-facing applications, route audio interactions through Nemotron 3 VoiceChat to eliminate cascaded pipeline complexity and hit sub-300ms latency targets.
Layer 4 — Safety Guardrails Wrap every input and output checkpoint with Nemotron 3 Content Safety. Moderate user messages, retrieved content, and final responses to maintain safety across all 23 harm categories.
Layer 5 — Evaluation and Optimization Instrument your entire stack with NeMo Evaluator and NeMo Agent Toolkit to benchmark performance, track costs, and identify bottlenecks before they become production incidents.
Actionable Next Steps: Get Started Today
NVIDIA Nemotron 3 is available now, with permissive open model licenses that support commercial deployment, fine-tuning, and on-premise hosting.
- Download models and datasets: Hugging Face — nvidia
- Preview Nemotron 3 Super: build.nvidia.com
- Access Nemotron 3 Content Safety: Hugging Face
- Apply for VoiceChat early access: build.nvidia.com/nvidia/voicechat
- Start evaluating: NeMo Evaluator on GitHub
- Start optimizing: NeMo Agent Toolkit on GitHub
- Explore hosted API endpoints: build.nvidia.com and OpenRouter
The Bottom Line
If your current AI system is just a larger model in the same chat window, you’re not building agentic AI—you’re building an expensive chatbot. True agentic systems require a coordinated stack of models, tools, memory, and guardrails that can plan, execute, critique, and adapt across complex, real-world workflows.
NVIDIA Nemotron 3 is the most comprehensive open answer to that challenge available today. Nemotron 3 Super handles long-context reasoning and planning with breakthrough efficiency on Blackwell hardware. Nemotron 3 Content Safety watches every checkpoint in the pipeline. Nemotron 3 VoiceChat makes intelligent agents genuinely conversational. The Llama Nemotron RAG models unlock every format of enterprise knowledge. And NeMo tools make the whole system measurable, optimizable, and production-ready.
The era of one-model AI is ending. The era of coordinated agentic systems—built on open, efficient, trustworthy components—is here.
1. What makes NVIDIA Nemotron 3 different from previous versions?
Unlike Nemotron-2, which focused primarily on raw language performance, Nemotron 3 is built specifically as an agentic stack. It introduces specialized models for the entire lifecycle of an AI agent, including hybrid Mamba-Transformer architectures for long-context reasoning, end-to-end voice models, and multimodal safety guardrails.
2. Can I run Nemotron 3 Super on consumer hardware?
While Nemotron 3 Super is a 120B parameter model, its Mixture-of-Experts (MoE) architecture only activates 12B parameters per pass. However, for production-grade performance with the 1M-token context window, NVIDIA Blackwell or Hopper (H100/H200) GPUs are recommended. For edge deployment or local testing, Nemotron 3 Nano is the better choice for RTX-powered PCs.
3. How does “VoiceChat” achieve sub-300ms latency?
Traditional voice AI uses a “cascade” (ASR → LLM → TTS), where each step adds latency. Nemotron 3 VoiceChat is an end-to-end model that processes audio input and generates audio output directly. By eliminating the middle steps and using streaming inference, it achieves human-like, full-duplex conversation speeds.
4. Is Nemotron 3 Content Safety only for text?
No. Nemotron 3 Content Safety (4B) is natively multimodal. It can simultaneously analyze text and images (such as user-uploaded screenshots or retrieved PDF pages) to detect risks across 23 harm categories, including hate speech, violence, and unauthorized advice.
5. What is “Multimodal RAG” and why do I need it?
Standard RAG only “reads” text. Multimodal RAG uses models like Llama Nemotron Embed VL to “see” documents. This allows your agent to retrieve information hidden in charts, tables, and infographics within PDFs or slide decks that text-only parsers would miss.
6. Where can I find the model weights and training data?
NVIDIA has released the Nemotron 3 family under a permissive open model license. You can download the weights, training recipes, and datasets directly from the NVIDIA organization on Hugging Face.