Artificial Intelligence (AI) ବିଜ୍ଞାନରେ Large Language Models (LLMs) ବଡ଼ ମାର୍ଗଦର୍ଶକ ଭାବେ ଦୃଶ୍ୟମାନ ହୋଇଛି। ଏଗୁଡ଼ିକ ଚାଟବଟ୍, କୋଡିଂ ଏବଂ କନ୍ଟେଣ୍ଟ ଲେଖିବା ଭଳି ବିଭିନ୍ନ କାମରେ ସଫଳ ଅଭିନୟ କରୁଛି। ଏହାର ଶକ୍ତି କାହିଁକି ଏତେ ଦୃଢ? ଏହାର ଆକାର୍ଯ୍ୟ ପ୍ରଣାଳୀ ଏବଂ ଯାଏଁ ତାଲେ ସମସ୍ୟା ହୋଇପାରେ, ତାହା ଆଲୋଚନା କରିବା ଦରକାର।
What is a Large Language Model (LLM)?
ଏକ Large Language Model (LLM) କି ଏକ ସ୍ୱତନ୍ତ୍ର ଅର୍ଥରେ ସରଳ କ୍ଷମତାର ଗଭୀର ନମୁନା ରାଜ୍ୟ। ଏହା ଜାତିୟ ଡାଟାସେଟ ଉପରେ ଶିକ୍ଷା ନେଉଥାଏ ଏବଂ ପ୍ରସଙ୍ଗ ଏବଂ ଶବ୍ଦର ସମ୍ପର୍କ ବୁଝିପାରେ। transformer architecture ମାଧ୍ୟମରେ, ଏହା ବହୁ ଲାଂଗୁଏଜ ଟାସ୍କ ସମାଧାନ କରିପାରେ।
ଉଦାହରଣ:
- GPT (Generative Pre-trained Transformer): ChatGPT ଏବଂ Codex ପାଇଁ ମୂଳ ଆର୍କିଟେକ୍ଚର।
- BERT (Bidirectional Encoder Representations from Transformers): Google ସର୍ଚ୍ଚରେ ଦେଖାଯାଏ।
- LLaMA: ଗବେଷଣା ଉଦ୍ଦେଶ୍ୟରେ ବ୍ୟବହୃତ ହୁଏ।
How Do LLMs Work?
LLM ମୂଳତଃ transformer architecture ଉପରେ ଆଧାରିତ। ଏହାର ଆର୍କିଟେକ୍ଚର ଗୁଡ଼ିକ ପର୍ଯ୍ୟାଲୋଚନା କରିବାରେ, ଏହାର ତ୍ୱରିତ ଲେଖା ଏବଂ ପ୍ରସଙ୍ଗ ବୁଝିବାକୁ ସମ୍ପୂର୍ଣ୍ଣ ସକ୍ଷମ।
Transformer ର ମୁଖ୍ୟ ଭାଗଗୁଡ଼ିକ
Input Embedding Layer:
- ଏହା ଶବ୍ଦକୁ ଏକ ମାଥମାତିକ ଭାବରେ ରୂପାନ୍ତର କରେ।
- ଉଦାହରଣ: “King” ଏବଂ “Queen” ଗୁଡ଼ିକ ସମାନ ସେମାଣ୍ଠି ସମ୍ପର୍କ ଥାଏ।
Positional Encoding:
- ଶବ୍ଦର ଅନୁକ୍ରମ ନିଶ୍ଚିତ କରିଥାଏ।
Multi-Head Attention:
- ପ୍ରତ୍ୟେକ ଶବ୍ଦର ସମ୍ପର୍କ ବୁଝିପାରେ। ଏହା Query (Q), Key (K), ଏବଂ Value (V) ଉପରେ କାର୍ଯ୍ୟ କରେ।
Feed-Forward Neural Network (FFN):
- ଏହା ମୂଖ୍ୟ ଆଇନପୁଟ ଆଉଟପୁଟ ରେ ଯୋଗାଯୋଗ ସୃଷ୍ଟି କରିପାରେ।
Output Layer:
- ଅନ୍ତିମ ପ୍ରତିଫଳ ଦିଏ।
Self-Attention କିପରି କାମ କରେ
ଏହା ଏକ ମହତ୍ତ୍ୱପୂର୍ଣ୍ଣ ଭାଗ ହେଉଛି। ଏହା ତାର ଅନୁପାତରେ ଏକ ଭାବାବେଗ ଶିକ୍ଷା ନେଇଥାଏ।
Self-Attention ର ଷ୍ଟେପ୍ସ:
- Query, Key, Value ଭଳି ଭିନ୍ନ ଭାଗର ସୃଷ୍ଟି।
- ସମ୍ଭାବନା ଏବଂ Softmax ମାଧ୍ୟମରେ ତାହାକୁ ନର୍ମାଲାଇଜ୍ କରାଯାଏ।
- Value ର weighted sum ମାଧ୍ୟମରେ ଫାଇନାଲ ଆଉଟପୁଟ ମିଳେ।
ଏଥିକି ଯାହା ଭିତରୁ Self-Attention Mechanism ଆକ୍ଷେପାଯୋଗ୍ୟ ହୁଏ। ତଳେ ଏହାର ଡାଗ୍ରାମ ଦିଆଯାଇଛି:

ଏହି ଡାଗ୍ରାମ ରେ, Query (Q), Key (K), ଏବଂ Value (V) ବିବରଣୀ ଦେଖାଯାଇଛି। ଡାଗ୍ରାମର ଭିତରେ ସଫ୍ଟମାକ୍ସ ଏବଂ ଏହାର ନର୍ମାଲାଇଜ୍ ଫ୍ଲୋ ସହିତ ସଂଯୁକ୍ତ ମୁଖ୍ୟ ସ୍ତରଗୁଡ଼ିକ ଉପସ୍ଥାପିତ।
LLM Training Process
ଏହାର ତିନି ମୁଖ୍ୟ ପର୍ଯ୍ୟାୟ ହେଉଛି: Pre-Training, Fine-Tuning, ଏବଂ Inference।
1. Pre-Training
- ଗୋଳ: ଏକ ବିଶାଳ ଡାଟାସେଟରୁ ଶିକ୍ଷା ନେବା।
- ଅବଜେକ୍ଟିଭ୍ସ: Causal ଏବଂ Masked Language Modeling।
ଉଦାହରଣ:
Input: “The cat sat on the…”
Predicted: “mat.”
2. Fine-Tuning
- ଗୋଳ: ନିର୍ଦ୍ଦିଷ୍ଟ କାମରେ ଆପ୍ଲିକେସନ ଏବଂ ପ୍ରସଙ୍ଗ ହେଉଥିବା ତଥ୍ୟ ଶିକ୍ଷା ନେବା।
- ତକନିକ: Reinforcement Learning with Human Feedback (RLHF)।
3. Inference
- ଗୋଳ: ପ୍ରାକ୍ତିକ କାମ ପାଇଁ ମଡେଲ୍ ପ୍ରୟୋଗ କରିବା।
ତଳେ ଏହାର ଡାଗ୍ରାମ ଦିଆଯାଇଛି:
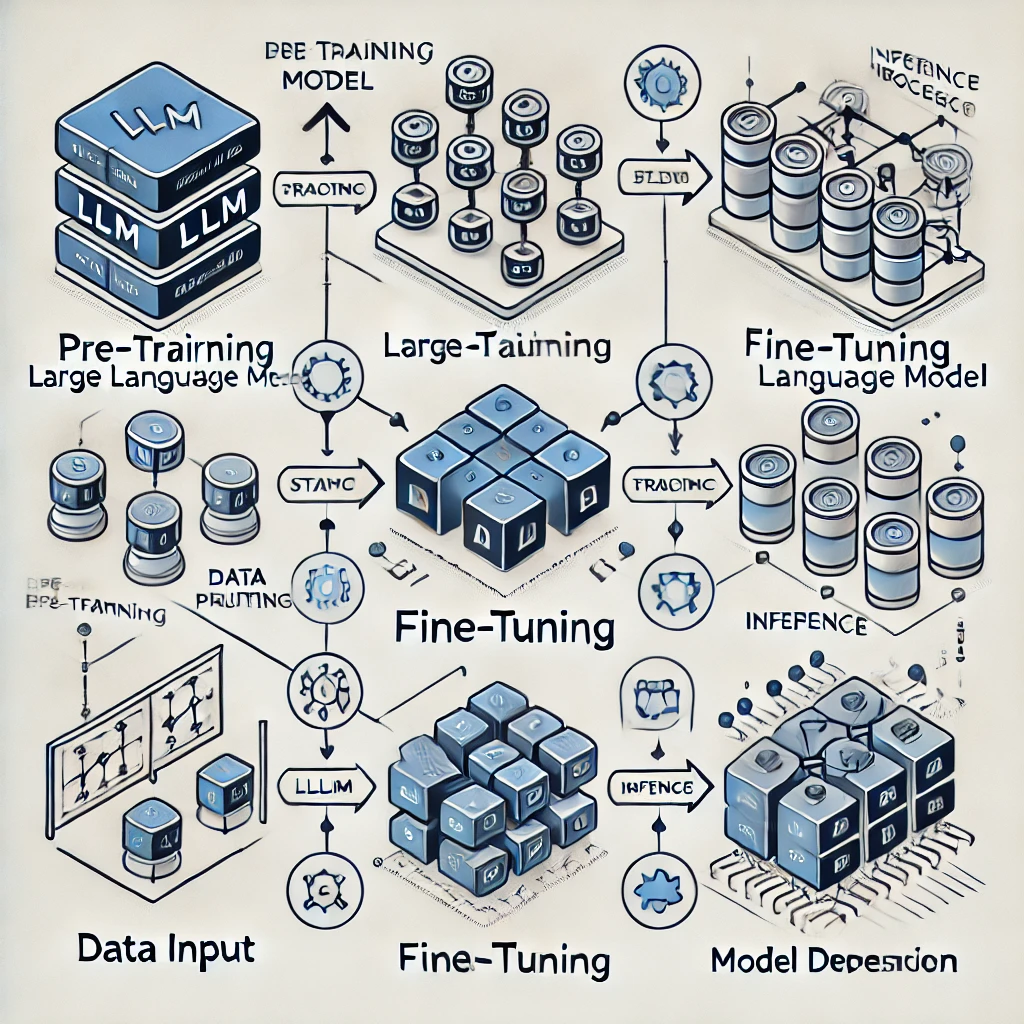
ଏହି ଡାଗ୍ରାମରେ Pre-Training ରୁ Inference ପର୍ଯ୍ୟନ୍ତ ଡାଟା ଫ୍ଲୋ ଓ ମୂଖ୍ୟ ଲକ୍ଷ୍ୟଗୁଡ଼ିକ ଦେଖାଯାଇଛି। ଅନ୍ତର୍ଭୁକ୍ତ ଆଇକନ ମଧ୍ୟ ଡାଟା ସଂଗ୍ରହଣରୁ ଆରମ୍ଭ କରି ମୂଖ୍ୟ ଉପଯୋଗ ପର୍ଯ୍ୟନ୍ତ ସବୁ ପ୍ରଦର୍ଶନ କରିଛି।
Challenges of LLMs
ଆଜିର ତାରିଖରେ Large Language Models (LLMs) ଆଖିରେ ଆଗରେ ଥିବା ଦୃଶ୍ୟ ଯେତେବେଳେ ବହୁ ଉତ୍ସାହଜନକ ଲାଗୁଥାଏ, ସେହି ସମୟରେ ଏହାର କେତେକ ଗୁରୁତ୍ୱପୂର୍ଣ୍ଣ ସମସ୍ୟା ଅଛି ଯାହାକୁ ସମାଧାନ କରିବା ଆବଶ୍ୟକ। ଆସନ୍ତୁ ଏହି ସମସ୍ୟାଗୁଡ଼ିକ ଗଭୀର ଭାବରେ ବୁଝିବା।
1. Hallucinations
Hallucination ହେଉଛି ଏକ ମୁଖ୍ୟ ସମସ୍ୟା ଯାହାରେ ମଡେଲ୍ ସଠିକ୍ ତଥ୍ୟ ଦେଇପାରେ ନାହିଁ ଓ ଏକ ଭୁଲ୍ କିମ୍ବା ନିରାର୍ଥକ ଉତ୍ତର ସୃଷ୍ଟି କରେ। ଏହା ମୁଖ୍ୟତଃ ଏପରି ସାମୟିକ ସ୍ଥିତିରେ ଘଟେ ଯେତେବେଳେ ମଡେଲର ଡାଟା ଟ୍ରେନିଙ୍ଗ ବିଶାଳ ହୋଇଥାଏ କିନ୍ତୁ ଏକ ସ୍ୱତନ୍ତ୍ର ସଠିକ୍ ଅର୍ଥ ବୁଝିପାରେ ନାହିଁ।
ଉଦାହରଣ:
- ପ୍ରଶ୍ନ: “Who was the first person to land on Mars?”
- ମଡେଲ ଉତ୍ତର: “Neil Armstrong,” ଯେଉଁକି ସଠିକ୍ ନୁହେଁ କାରଣ ସେ ଆମ୍ରିକାର ଚନ୍ଦ୍ର ଅଭିଯାନରେ ଯାଇଥିଲେ, ମାର୍ସରେ ନୁହେଁ।
Hallucination ର କାରଣ:
- Incomplete Data: ମୂଳ ତଥ୍ୟ ଅନୁପଲବ୍ଧ ଥାଇପାରେ।
- Pattern Matching Errors: ମଡେଲ କେବଳ ତଥ୍ୟର ସଂଗଠନର ଆଧାରରେ ଚିନ୍ତା କରେ ଏବଂ ତାହାର ସଠିକ୍ ରୁପରେ ପ୍ରତିନିଧିତ୍ୱ କରେ ନାହିଁ।
ଏହାର ପ୍ରତିଫଳ:
- ଅଣଶିକ୍ଷିତ ବା ଭୁଲ୍ ଉତ୍ତର।
- ସ୍ୱତନ୍ତ୍ର କ୍ଷେତ୍ରରେ ଅନୁଶାସନର ଅଭାବ।
2. Bias
Bias ହେଉଛି ଏକ ସମସ୍ୟା ଯାହା ବୃହତ୍ ସମାଜିକ ଏବଂ ସାଂସ୍କୃତିକ ପ୍ରଭାବ ବୁଝାଏ। ମଡେଲର ଡାଟା ଏହାକୁ ପ୍ରଶ୍ନବାହୁଳ କରିପାରେ କାରଣ ଏହି ଡାଟା ବହୁତ ସମୟରେ ଆଗୁଆ ନାହିଁ।
ଉଦାହରଣ:
ଯଦି ମଡେଲ୍ “doctor” କୁ ପୁରୁଷ ଏବଂ “nurse” କୁ ସ୍ତ୍ରୀ ଥିବା ଭାବରେ ଜଣାଇଥାଏ, ସେହିପରି ନିର୍ଦ୍ଦିଷ୍ଟ bias ଦେଖାଯାଏ।
Bias ର କାରଣ:
- Training Data Bias: ଏହାର ଡାଟା ବୃହତ୍ ଭାବରେ ସମାନ ତଥ୍ୟ ଯୋଗାଇ ଦିଆଯାଇ ନଥାଏ।
- Cultural Representation: ସମାନତାର ଅଭାବର ଫଳରେ bias ସୃଷ୍ଟି ହୁଏ।
ଏହାର ପ୍ରତିଫଳ:
- ଅନୁପ୍ରସଙ୍ଗୀ bias ଅଭିବ୍ୟକ୍ତି।
- ଏକ ବୃହତ୍ ସମାଜର ସ୍ପଷ୍ଟ ସୂଚନାର ଅଭାବ।
3. Resource-Intensive Training
LLMs ଟ୍ରେନ କରିବାରେ ବଡ଼ ମାତ୍ରାର ରିସୋର୍ସ ଆବଶ୍ୟକ ହୁଏ। ବୃହତ୍ ଡାଟାସେଟରେ ଏହାକୁ ଟ୍ରେନ କରିବାରେ ସଂପୂର୍ଣ୍ଣ ଭାବରେ ଏକ ବଡ଼ ମାଲ୍ୟ ଲାଗେ।
ସଂପୂର୍ଣ୍ଣ ମୁଖ୍ୟ ସମସ୍ୟାଗୁଡ଼ିକ:
- Energy Consumption: ଏକ GPT-3 ମଡେଲ ଟ୍ରେନ କରିବା ପାଇଁ ବହୁତ ଇନର୍ଜି ଲାଗୁଛି। ଏହା ପରିବେଶରେ ପ୍ରଭାବିତ ହୋଇପାରେ।
- Computational Costs: ଏହାକୁ ଡିପ୍ ଲେଭେଲରେ ଏକ ଲାର୍ଜ ଡିସ୍ଟ୍ରିବ୍ୟୁଟେଡ୍ ସିଷ୍ଟେମ ଆବଶ୍ୟକ।
ଏହାର ପ୍ରତିଫଳ:
- ଅଭ୍ୟାସକୁ ସମ୍ପୂର୍ଣ୍ଣ କରିବାରେ ଦୀର୍ଘ ସମୟ।
- ଗ୍ରୀନ ଏନର୍ଜି ଏବଂ ଆକାର୍ଯ୍ୟକ୍ଷମ ହୋଇପାରୁ ଲୋକପ୍ରିୟ ନୁହେଁ।
4. Data Privacy
ଏହି ମଡେଲର ଆଧାରରେ ତଥ୍ୟ ସଂଗ୍ରହଣ ଯାହାକି ବ୍ୟକ୍ତିଗତ ଆଧାରରେ ଆକ୍ଷେପାଯୋଗ୍ୟ। ଏହାର ଉପଯୋଗରେ sensitive data ତୃତୀୟ ପକ୍ଷ ଦ୍ୱାରା ହାତେ ପଡ଼ିପାରେ।
ଏହାର କାରଣ:
- Insufficient Anonymization: ଡାଟାକୁ ନିଜ ସ୍ୱତନ୍ତ୍ର ଭାବରେ ସୁରକ୍ଷା ଦେଇ ନଥାଏ।
- Over-Reliance on Public Data: ଜାନା ଡାଟାରୁ ସମାନ ତଥ୍ୟ ଫିରାଇଦେଉଥାଏ।
ଏହାର ପ୍ରତିଫଳ:
- ସମ୍ବେଦନଶୀଳ ତଥ୍ୟର ଚୁରି।
- ଡାଟା ବ୍ୟବସ୍ଥାପନରେ ଗୁପ୍ତତା ରକ୍ଷାର ଅଭାବ।
ଏହି ସମସ୍ୟାଗୁଡ଼ିକ ସମାଧାନ ପାଇଁ ଏକ ନୂଆ ମାର୍ଗଦର୍ଶନ ଅବଶ୍ୟକ।
ଆପଣ ଏହା ବାବଦରେ ଅଧିକ ତଥ୍ୟ ଆଲୋଚନା କରିବାକୁ ଚାହିଁବେ?