How does SGLang work? SGLang works by combining a smart caching technique called RadixAttention with continuous batching and constrained decoding, so it can reuse previously computed work instead of repeating it for every user. The result is a serving framework that answers thousands of requests to a large language model at once, without wasting compute on text it has already processed.
If you have ever wondered why some AI chat products feel instant while others lag under load, the answer often comes down to the serving engine underneath the model. Understanding how SGLang works starts with understanding the problem it solves and the mechanics that make it fast — so let’s break both down in plain language, with no unnecessary jargon.
What Is SGLang?
SGLang is an open-source serving framework for large language models (LLMs) and multimodal models. Its job is to take a trained model and serve responses to many users simultaneously, as efficiently as possible.
The name breaks down into two parts:
- SG stands for Structured Generation — the ability to force model output into a reliable, predictable format.
- Lang stands for Language — a lightweight programming interface for describing multi-step prompts.
SGLang is built from two main components that work together:
- A runtime, which is the execution engine that actually runs the model, manages memory, and handles structured output.
- A frontend language, a small Python-embedded language that lets developers describe multi-step interactions with the model in a natural, readable way.
To understand how SGLang works and why it’s fast, it helps to first understand how an LLM generates text in the first place.
A Quick Recap: How an LLM Generates Text
An LLM produces text one token at a time. A token is a small chunk of text — sometimes a whole word, sometimes part of one. For simplicity, you can think of a token as roughly equivalent to one word.
Here’s the process:
- The model reads the input.
- It generates the next token.
- It reads the input plus that new token.
- It generates the following token.
- This repeats until the response is complete.
For example, given the prompt “The sky is,” the model first reads that phrase and outputs “blue.” Then it reads “The sky is blue” and outputs the next token, and so on.
Notice that every new token requires the model to look back at everything generated so far. Recomputing this from scratch at every step would be extremely slow. So instead, the model stores intermediate values from previous tokens and reuses them. This stored memory is called the KV cache (short for key-value cache).
The KV cache is the model’s saved computational work for tokens it has already processed, so it doesn’t need to redo that work for every new token generated.
This single idea — reusing saved computation instead of repeating it — is the foundation that SGLang builds on at a much larger scale.
The Problem SGLang Solves
In production, an LLM rarely serves one person in isolation. It answers thousands of requests concurrently, and many of those requests share large chunks of identical text.
Consider a chatbot application. Every conversation begins with the same system prompt — a fixed instruction such as “You are a helpful assistant.” Without any optimization, the model reprocesses this identical text for every single user, every single time.
Or consider a document question-answering agent. The underlying document doesn’t change between questions, yet a naive setup would re-read the entire document from scratch for each new question — like rereading an entire book from page one just to answer a single follow-up question.
This repeated, wasted computation is exactly the inefficiency SGLang was designed to eliminate. The central insight behind SGLang is simple:
If two requests share the same starting text, they should be able to share the saved computational work for that text, instead of recomputing it separately.
The mechanism that makes this sharing possible is called RadixAttention, and it’s the technical heart of SGLang.
RadixAttention: The Core Innovation Behind How SGLang Works
RadixAttention is the technique SGLang uses to automatically detect and reuse shared KV cache across multiple requests. It combines two ideas: a radix structure for organizing text by shared prefixes, and attention, the core mechanism LLMs use to reference previous tokens.
What Is a Prefix, and What Is a Radix Tree?
A prefix is the portion of text that two or more pieces of text have in common at the start. For example, “The sky is blue” and “The sky is clear” share the prefix “The sky is.”
SGLang organizes the KV cache of many concurrent requests into a radix tree — a tree structure that groups requests by their shared prefixes, splitting into separate branches only where the text diverges. Think of it as a family tree for sentences: requests that start the same way share a branch, and they only separate once their content actually differs.
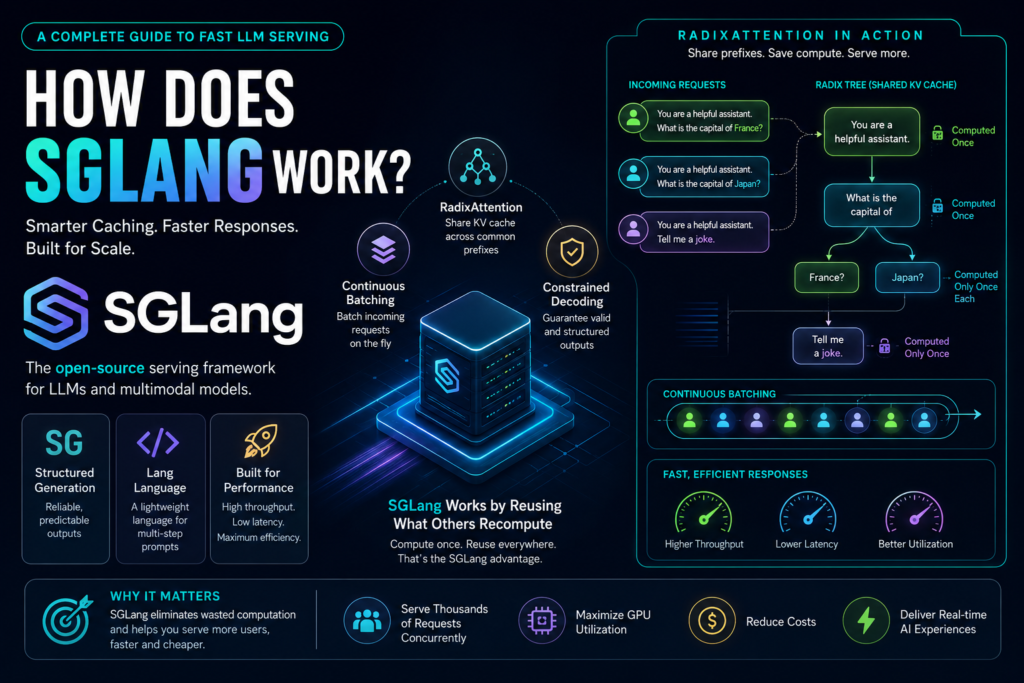
A Concrete Example of RadixAttention in Action
Imagine three users send these requests to a chatbot at roughly the same time:
- “You are a helpful assistant. What is the capital of France?”
- “You are a helpful assistant. What is the capital of Japan?”
- “You are a helpful assistant. Tell me a joke.”
All three share the prefix “You are a helpful assistant.” Without SGLang’s approach, the model would process that shared prefix three separate times — pure wasted compute.
With RadixAttention, the shared prefix is computed once and stored in the radix tree. Any request sharing that prefix reuses it immediately. Going further, the two capital-city questions also share “What is the capital of,” so that portion becomes its own shared branch, computed only once as well. Only the truly unique parts — “France?”, “Japan?”, and “Tell me a joke.” — get processed fresh.
This is how RadixAttention turns three overlapping requests into a fraction of the original compute cost.
How RadixAttention Reuses Past Work Step by Step
When a new request arrives, SGLang follows a predictable sequence:
- A new request comes in — for example, “You are a helpful assistant. What is the capital of Italy?”
- SGLang checks the radix tree to see how much of the request’s beginning already exists there.
- It finds a match for “You are a helpful assistant. What is the capital of” from earlier requests, and reuses that cached computation instead of recalculating it.
- Only the new portion — “Italy?” — gets processed fresh, and the result is added to the tree as a new branch.
- The model then generates its answer token by token, as described earlier.
Because memory is finite, SGLang can’t keep every cached branch forever. When space runs low, it uses a least recently used (LRU) eviction policy — the branches that haven’t been accessed in the longest time get removed first. This means popular shared prefixes, like common system prompts, tend to stay cached, while rare one-off text gets cleared out to make room. This design is what allows SGLang to sustain high reuse rates even under heavy, varied traffic.
SGLang’s Frontend Language for Multi-Step Prompts
Beyond the runtime engine, SGLang includes a frontend language — a way of writing multi-step prompt logic directly inside Python code.
Real-world LLM tasks are rarely a single question-and-answer exchange. A typical task might involve reading a paragraph, summarizing it, and then translating that summary — three dependent steps. Coordinating this manually while preserving speed and cache reuse is difficult to do well by hand.
The SGLang frontend language solves this by letting developers describe a sequence of model calls, mix in custom text, and capture outputs into named variables. Here’s a simplified illustration of the pattern:
import sglang as sgl
@sgl.function
def summarize_and_translate(s, paragraph):
s += "Summarize this paragraph:\n" + paragraph + "\n"
s += "Summary: " + sgl.gen("summary", max_tokens=64)
s += "Now translate the summary to French.\n"
s += "French: " + sgl.gen("french", max_tokens=64)
In this snippet, the variable s accumulates the growing conversation, and each sgl.gen() call generates a piece of output and stores it under a named key. Because the frontend understands the structure of the program, it naturally exposes which parts are shared and repeated across calls — which the runtime then exploits through RadixAttention. The frontend and runtime are explicitly designed to work together: the frontend reveals the structure, and the runtime turns that structure into speed.
How Continuous Batching Keeps SGLang Fast
Another technique that keeps SGLang efficient — though not unique to it — is continuous batching.
A batch is a group of requests processed together at the same time, which is far more efficient than handling requests one by one. The catch with traditional batching is that different requests finish at different times. Some users want short answers, others want long ones, and if the system waits for the entire batch to finish before starting new work, fast requests get stuck waiting on slow ones.
Continuous batching solves this by immediately filling any freed slot with the next waiting request, rather than waiting for the whole batch to complete. Here’s the difference visualized:
- Old-style batching: A slot that finishes early sits idle until every other request in the batch is also done — wasted capacity.
- Continuous batching: The moment a slot frees up, a new waiting request starts in it immediately — no idle time.
This keeps hardware utilization consistently high and lets SGLang serve more users in the same amount of time. On its own, continuous batching is common across modern serving engines. What makes SGLang distinctive is pairing continuous batching with RadixAttention — one keeps the hardware constantly busy, and the other minimizes redundant computation. Together, they compound each other’s benefits, especially in workloads with heavy prefix overlap like chatbots and agents.
Structured Output and Constrained Decoding
Remember that “SG” in SGLang stands for Structured Generation — and this is where that name delivers on its promise.
Applications frequently need output in a strict format, such as JSON:
{
"name": "Italy",
"capital": "Rome"
}
A plain, unconstrained model can produce slightly malformed JSON — a missing bracket, extra commentary, or inconsistent formatting — which then breaks any downstream program trying to parse it.
SGLang addresses this with constrained decoding, a technique where the model is only permitted to choose tokens that keep the output valid for the target format. Any token that would break the required structure is excluded from consideration at that step. This guarantees the output always conforms to the format you specify — no more broken JSON.
There’s an added performance benefit: because parts of a structured format are already predetermined by the schema, SGLang can sometimes fill in those fixed portions rapidly instead of generating them token by token, making structured generation faster as well as more reliable.
How Does SGLang Work End to End? A Simple Request Flow
Putting all these pieces together, here’s exactly how SGLang works when a request flows through the system from start to finish:
- The task is described using the SGLang frontend language, including the steps and desired output format.
- The request is sent to the SGLang runtime (the execution engine).
- The runtime checks the radix tree for any matching shared prefix — such as a system prompt — and reuses the cached KV data via RadixAttention if found.
- Only the new, unique portion of the request is processed fresh, and it’s added to the radix tree for future reuse.
- The request joins an active batch; continuous batching ensures the engine stays fully utilized.
- The model generates the response token by token, with constrained decoding enforcing any required structure.
- The finished response is returned — generated quickly and shaped correctly.
This pipeline is why SGLang performs particularly well in scenarios with heavy shared context: multi-turn conversations, AI agents, and document-grounded question answering.
More Powerful Features of SGLang
SGLang’s core flow — RadixAttention, the frontend language, continuous batching, and constrained decoding — covers the fundamentals, but the framework includes several additional capabilities worth knowing about:
- Chunked prefill — long prompts (like large documents) are broken into smaller chunks and processed incrementally, rather than blocking the entire system while one huge prompt is read.
- Speculative decoding — a smaller, faster helper model guesses several tokens ahead, and the main model verifies them in a single pass, speeding up generation when guesses are correct.
- Prefill and decode disaggregation — since the prefill stage (reading the prompt) and decode stage (generating tokens) have different resource needs, SGLang can run them on separate, specialized machines for better efficiency at scale.
- Multi-GPU and multi-node model splitting — very large models, including mixture-of-experts architectures, can be split across many GPUs or even many machines so they fit and run efficiently.
- Quantization — model weights are compressed into smaller numerical formats, reducing memory usage and increasing speed with minimal quality loss.
- Serving multiple fine-tuned variants together — several small, task-specific model variants built on the same base model can be served in a shared batch instead of requiring separate deployments.
- Multimodal support — SGLang isn’t limited to text; it also serves models that process images, with ongoing support for additional modalities like video.
- Cache-aware load balancing — across multi-machine deployments, SGLang routes requests toward machines that already hold relevant cached data, preserving RadixAttention’s benefits even at a distributed scale.
These features illustrate that SGLang is a full-fledged, production-grade serving platform, not just a single clever trick — although RadixAttention remains its most distinctive contribution.
SGLang vs vLLM: Which Should You Choose?
A common question when evaluating LLM serving frameworks is how SGLang compares to vLLM, another widely used serving engine. Both are mature, high-performance tools, and over time their capabilities have converged significantly. Both reuse cached computation, support high-throughput batching, and can produce structured output — so the differences are more about emphasis than raw capability.
| Comparison Point | vLLM | SGLang |
|---|---|---|
| Prefix/cache reuse method | Fixed-size memory blocks (PagedAttention) | Precise, piece-by-piece matching via a radix tree (RadixAttention) |
| Community and track record | Larger and more established | Newer, but growing rapidly with large-scale production use |
| Distinctive strength | General-purpose serving maturity | Prefix sharing efficiency, frontend language, structured output |
| Best suited for | Diverse, largely unrelated requests | Multi-turn chat, agents, and document Q&A with heavy shared context |
The practical takeaway: if your workload consists of many largely unrelated requests and you want the most established, widely adopted option, vLLM is a strong choice. If your workload involves heavy repeated context — long conversations, agentic workflows, or repeated document queries — SGLang’s finer-grained prefix matching tends to shine. Raw throughput differences between the two vary by model, hardware, and version, so neither holds a permanent, universal speed advantage.
Frequently Asked Questions About SGLang
How does SGLang work in simple terms? SGLang works by caching and reusing shared text computation through RadixAttention, keeping hardware busy through continuous batching, and enforcing valid output formats through constrained decoding — all coordinated through its frontend language and runtime engine.
What does SGLang stand for? SGLang stands for “Structured Generation Language,” reflecting its two core capabilities: generating reliably structured output and providing a lightweight language for describing prompt logic.
What is RadixAttention in SGLang? RadixAttention is the caching mechanism SGLang uses to detect shared text prefixes across requests and reuse their computed KV cache, avoiding redundant computation.
Is SGLang faster than vLLM? Neither tool has a consistent, universal speed advantage — performance depends on the model, hardware, and workload. SGLang tends to excel specifically in workloads with heavy shared context.
Does SGLang support JSON and other structured outputs? Yes. SGLang uses constrained decoding to guarantee that generated output always conforms to a specified schema or format, such as valid JSON.
Can SGLang serve multimodal models? Yes, SGLang serves models that process images in addition to text, with expanding support for other modalities.
Final Thoughts: How Does SGLang Work, and Why It Matters
In summary, how does SGLang work? It works by attacking the biggest source of waste in LLM serving: redundant computation on text that’s already been processed. Through RadixAttention’s precise prefix matching, continuous batching’s constant hardware utilization, and constrained decoding’s reliable structured output, SGLang delivers a serving framework that’s both fast and predictable. For teams building chatbots, AI agents, or document-grounded applications where requests frequently share context, SGLang’s architecture is purpose-built to turn that overlap into real, measurable performance gains.