Artificial Intelligence (AI) has transformed how we interact with technology, and Large Language Models (LLMs) are leading this revolution. From chatbots and virtual assistants to content creation and healthcare, LLMs are reshaping industries. But how do they work? What makes them so powerful? Let’s dive deeper to uncover the architecture, applications, challenges, and future of LLMs.
What is a Large Language Model (LLM)?
A Large Language Model (LLM) is an AI system designed to understand and generate human-like text. These models are trained on enormous datasets that include text from books, articles, and websites. They are built on the transformer architecture, which makes them exceptionally good at understanding the context and relationships between words.
What Sets LLMs Apart?
- Scale: LLMs like GPT-4 can have hundreds of billions of parameters.
- Contextual Understanding: They excel at capturing relationships between words over long contexts.
- Versatility: They can handle a wide variety of tasks without task-specific programming.
Popular examples include:
- OpenAI’s GPT Series: ChatGPT and Codex.
- Google’s BERT: Used in search engines and NLP tasks.
- Meta’s LLaMA: An open-source model optimized for research.
How Do LLMs Work?
At the heart of LLMs is the transformer architecture, introduced by Google in their groundbreaking 2017 paper “Attention Is All You Need”.
Key Components of the Transformer
- Input Embedding Layer
- Converts words or tokens into dense vectors that represent their meaning.
- Embeddings capture semantic relationships. For example, “king” and “queen” would have similar embeddings.
- Positional Encoding
- Adds information about the position of words in a sentence. Without this, transformers would treat sequences as unordered.
- Multi-Head Attention
- Allows the model to focus on different parts of the input simultaneously.
- Breaks down the input into query (Q), key (K), and value (V) vectors.
- Computes attention scores to decide which words are most important for a given context.
- Feed-Forward Neural Network (FFN)
- Applies non-linear transformations to the attention output, enabling complex learning.
- Layer Normalization
- Stabilizes training by normalizing the output of each layer.
- Output Layer
- Produces the final predictions, such as the next word in a sentence or a translation.
Below is a visual representation of the transformer architecture:
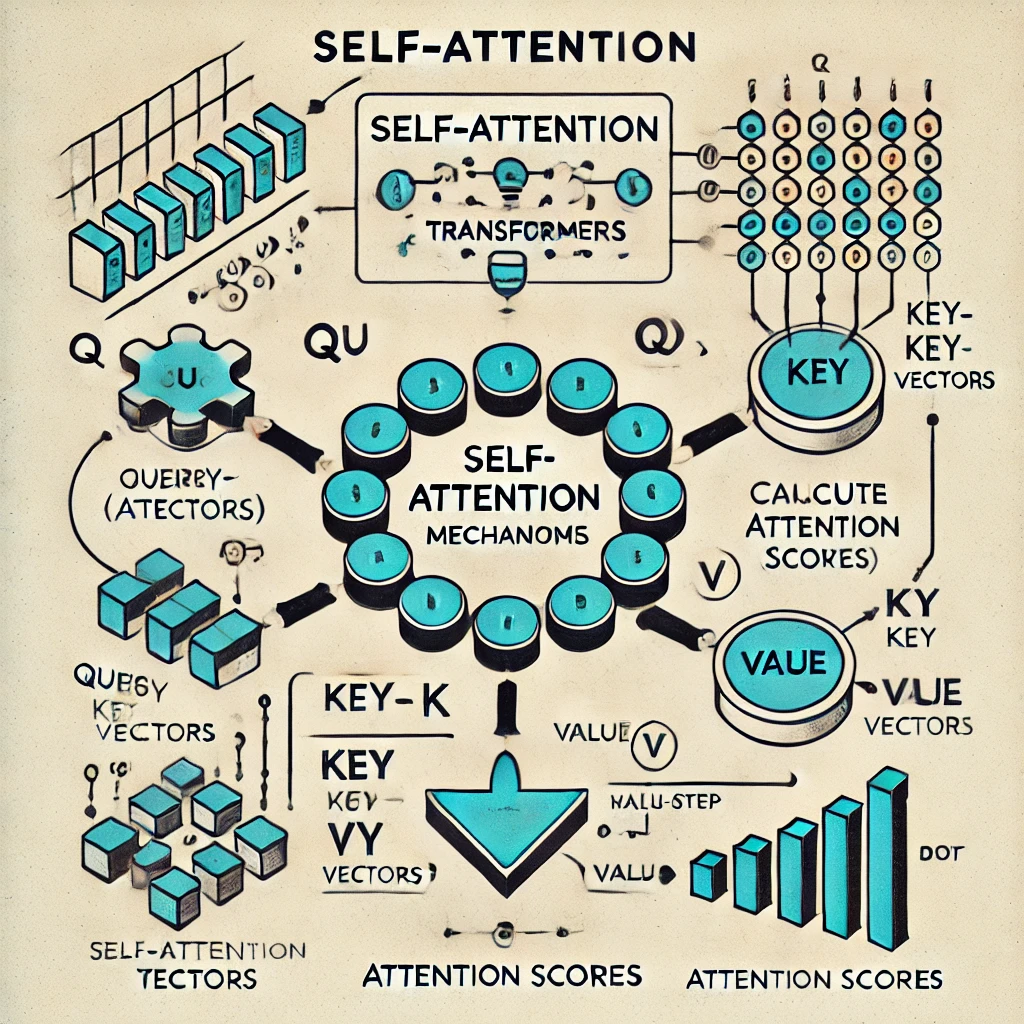
Self-Attention in Detail
Self-attention is the mechanism that allows transformers to understand the relationships between words. It computes the relevance of every word in the sequence to every other word.
Steps in Self-Attention:
- Generate Q, K, V Vectors
- Each word is transformed into three vectors: Query (Q), Key (K), and Value (V).
- Compute Attention Scores
- The relevance of each word is calculated by taking the dot product of Q and K vectors.
- Apply Softmax
- Normalizes the scores into probabilities.
- Weighted Sum of Values
- Multiplies the Value (V) vector with the normalized scores to produce the attention output.
Below is a detailed diagram of the self-attention mechanism:
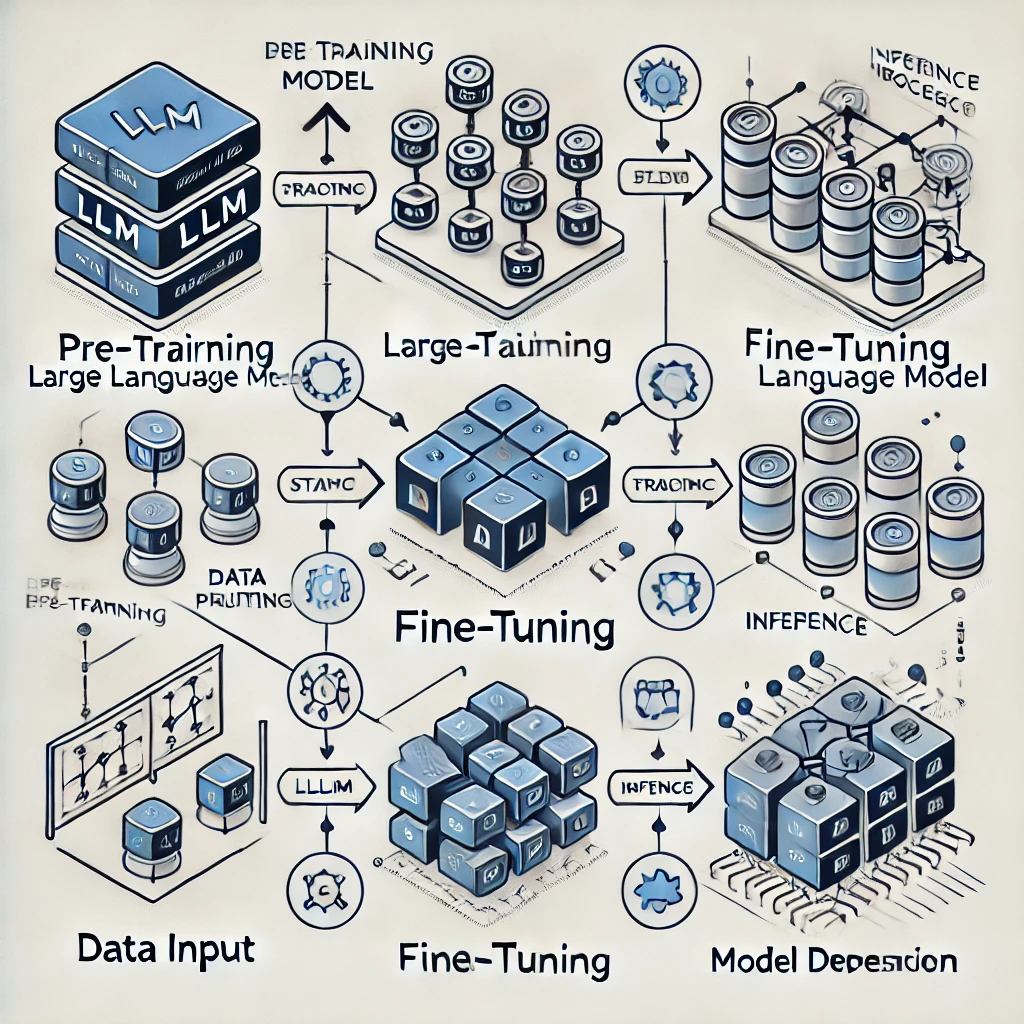
The Training Process of an LLM
Training a large language model is computationally intensive and involves the following stages:
1. Pre-Training
- Goal: Learn general patterns of language from a massive dataset.
- Objective Functions:
- Causal Language Modeling: Predict the next word based on previous words (used in GPT models).
- Masked Language Modeling: Predict missing words in a sentence (used in BERT).
For example, in masked language modeling:
- Input: “The cat [MASK] on the mat.”
- Output: “sat.”
2. Fine-Tuning
- Goal: Adapt the pre-trained model to specific tasks or domains.
- Dataset: Task-specific data like medical texts or legal documents.
- Techniques:
- Instruction Tuning: Fine-tune models using task instructions for better generalization.
- RLHF (Reinforcement Learning with Human Feedback): Aligns models with human preferences (used in GPT-4).
3. Inference
- Goal: Use the trained model for real-world tasks.
- Process: The model generates outputs (e.g., text completions) based on input prompts.
Below is a block diagram showing these stages:
Applications of LLMs
LLMs have unlocked new possibilities across multiple domains:
1. Conversational AI
- ChatGPT, Google Bard, and Alexa use LLMs for natural, human-like interactions.
2. Content Creation
- Generate blogs, marketing content, and creative writing.
3. Code Generation
- Tools like GitHub Copilot assist developers by suggesting code and debugging.
4. Language Translation
- LLMs like DeepL provide accurate, context-aware translations.
5. Scientific Research
- Summarize research papers, assist in drug discovery, and simulate protein folding.
Challenges of LLMs
Despite their power, LLMs face significant challenges:
- Hallucinations:
- The model generates plausible but incorrect or nonsensical outputs.
- Example: Misinterpreting a question and creating false information.
- Bias:
- Reflects societal and cultural biases present in training data.
- Resource-Intensive:
- Training LLMs requires vast computational resources and energy.
- Data Privacy:
- Models trained on sensitive data can inadvertently generate private information.
The Future of LLMs
The future of LLMs lies in addressing challenges while expanding their capabilities:
1. Efficient Models
- Developing smaller, faster models for edge devices and mobile applications.
2. Multi-Modal Models
- Integrating text, image, audio, and video understanding into a single model.
3. Improved Ethical Standards
- Reducing bias, improving transparency, and ensuring data privacy.