In the rapidly evolving world of artificial intelligence, speed and efficiency are the new gold standards. While the industry has been dominated by “autoregressive” models—the tech behind giants like ChatGPT and Claude—a new contender has emerged to challenge the status quo. Enter Inception Labs Mercury-2 Diffusion, a revolutionary model that promises to redefine how we interact with generative AI.
By moving away from the traditional “one-token-at-a-time” approach, Inception Labs has created a system that isn’t just a marginal improvement; it is a leap forward. In this post, we’ll dive deep into what makes Inception Labs Mercury-2 Diffusion so special and why it might just be the “speed king” the industry has been waiting for.
What is Inception Labs Mercury-2 Diffusion?
At its core, Inception Labs Mercury-2 Diffusion is a large language model (LLM) that utilizes a diffusion-based architecture rather than the standard autoregressive method. While traditional AI models predict the next word in a sequence—much like a very sophisticated version of autocomplete—Mercury-2 takes a different path.
Developed by Inception Labs, led by CEO and Stanford professor Stefano Ermon, this model applies the principles used in image generation (like Stable Diffusion) to the world of text and reasoning. The result? A model that can process and generate information with unprecedented velocity.
10x Faster Than the Competition
The most headline-grabbing feature of Inception Labs Mercury-2 Diffusion is its speed. According to recent benchmarks and statements from the company, this model is up to 10 times faster than industry leaders like GPT-4, Claude 3.5, and Gemini.
For developers and enterprises, this speed isn’t just about saving a few seconds; it’s about enabling real-time applications that were previously impossible. Whether it’s real-time coding assistance, instant customer support, or complex data synthesis, the efficiency of Inception Labs Mercury-2 Diffusion opens doors to a new era of “instant AI.”
Diffusion vs. Autoregressive: The Technical Breakthrough
To understand why Inception Labs Mercury-2 Diffusion is so fast, we have to look at how it “thinks.”
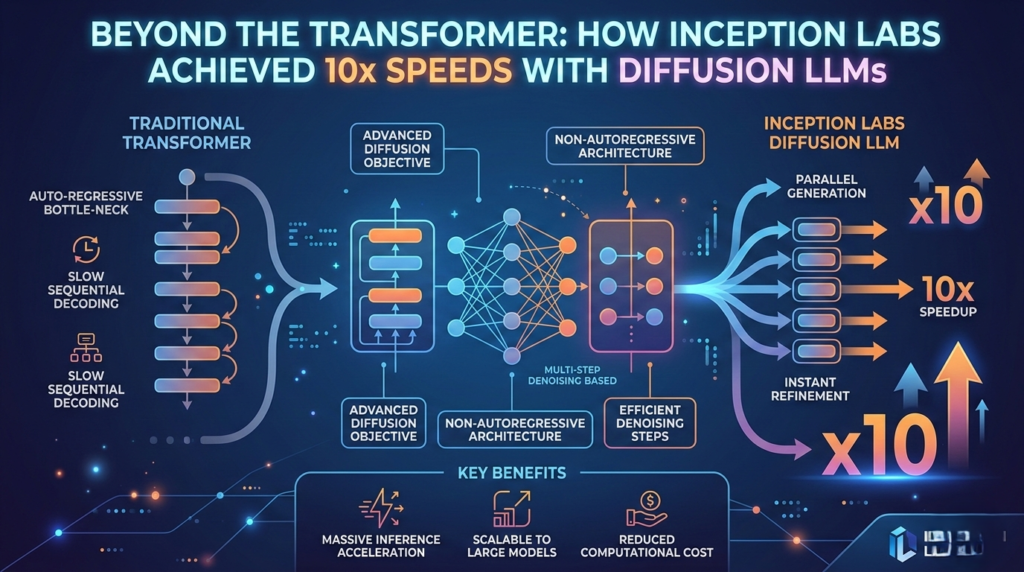
- The Autoregressive Way: Traditional LLMs generate text linearly. If you ask for a 100-word summary, the AI writes word #1, then word #2, then word #3, and so on. Each step depends on the one before it, creating a bottleneck.
- The Diffusion Way: Inception Labs Mercury-2 Diffusion works in parallel. It starts with a “noisy” or rough version of the entire answer and refines it across the board simultaneously. It’s like a sculptor carving a statue by working on the whole block at once rather than 3D printing it one layer at a time.
This parallel processing is the secret sauce that allows Inception Labs Mercury-2 Diffusion to bypass the sequential limitations of older models.
Key Features and Benefits
Beyond raw speed, Inception Labs Mercury-2 Diffusion offers several strategic advantages for the modern tech stack:
- Reduced Latency: Perfect for agentic workflows where multiple AI steps happen in succession.
- Cost Efficiency: Faster processing often translates to lower compute costs, making high-level AI more accessible for startups.
- Enhanced Reasoning: By refining an entire thought at once, diffusion models can potentially avoid some of the “logical dead ends” that linear models face.
- Scalability: The architecture of Inception Labs Mercury-2 Diffusion is designed to handle high-throughput demands without the lag typically associated with massive LLMs.
Is This the End of “Fancy Autocomplete”?
Inception Labs CEO Stefano Ermon has often referred to current LLMs as “fancy autocomplete.” While these models are incredibly capable, their linear nature is inherently limited. Inception Labs Mercury-2 Diffusion represents a shift toward “holistic generation.”
By treating text generation as a refinement process rather than a prediction chain, Inception Labs is moving the industry toward a more human-like way of conceptualizing information—where the “big picture” is established before the fine details are polished.
How to Integrate Mercury-2 into Your Workflow
For developers looking to stay ahead of the curve, keeping an eye on Inception Labs Mercury-2 Diffusion is essential. As AI agents become more prevalent, the need for low-latency models will skyrocket.
Integrating a tool like Inception Labs Mercury-2 Diffusion into your API landscape can significantly reduce the “wait time” for end-users, creating a much more seamless and “human” interaction. As we see more support for this architecture in frameworks like LangChain or AutoGPT, the adoption of diffusion-based text models is expected to explode.
Conclusion: The New Standard for AI Performance
The launch of Inception Labs Mercury-2 Diffusion marks a pivotal moment in the AI arms race. It proves that we don’t just need bigger models; we need smarter architectures. By delivering 10x speeds and a more efficient way to process language, Inception Labs has set a new benchmark for what generative AI can achieve.
As the tech community moves away from simple chatbots and toward complex, autonomous AI agents, the speed and parallel-processing power of Inception Labs Mercury-2 Diffusion will likely become the foundation for the next generation of digital innovation.
The Road Ahead: Scaling Diffusion LLMs in Production
While the benchmark of 10x speed improvement is a monumental milestone, the transition from Transformers to Diffusion LLMs represents more than just a raw performance metric; it is a fundamental shift in how we approach Agentic Workflows. In traditional autoregressive models, every token generated is a mandatory computational tax. By shifting to a non-autoregressive architecture, Diffusion LLMs effectively decouple sequence length from latency through a denoising-based approach.
For organizations currently struggling with high VRAM overhead and the “Time to First Token” (TTFT) lag, the evolution toward Diffusion LLMs offers three distinct operational advantages. First, these models provide deterministic latency. Unlike traditional decoding, Diffusion LLMs allow for parallel refinement, making response times predictable for real-time marketing automation.
Second, the reduced compute footprint of Diffusion LLMs allows teams to achieve higher throughput on existing hardware. By optimizing Diffusion LLMs, enterprises can reduce their dependency on high-end clusters, lowering the total cost of ownership. Finally, Diffusion LLMs offer enhanced controllability. The iterative nature of these models allows for “guidance” techniques during the denoising process, offering finer control over the output than standard sampling.
As we move through 2026, the integration of RAG with Diffusion LLMs will likely become the gold standard for enterprise AI. Understanding the mechanics of Diffusion LLMs is no longer just a research interest—it is a competitive necessity. The bottleneck is no longer the model’s ability to “think,” but our ability to serve those thoughts at the speed of business using Diffusion LLMs.