In the rapidly evolving world of artificial intelligence, moving from a flashy demo to a reliable production-grade tool is the ultimate hurdle. For a logistical giant like DoorDash, “reliable” isn’t just a buzzword—it is a requirement for thousands of daily interactions. Traditionally, customer support automation relied on rigid, predictable decision trees. However, as DoorDash transitioned to generative AI, they faced a new challenge: how do you test a system that is inherently unpredictable?
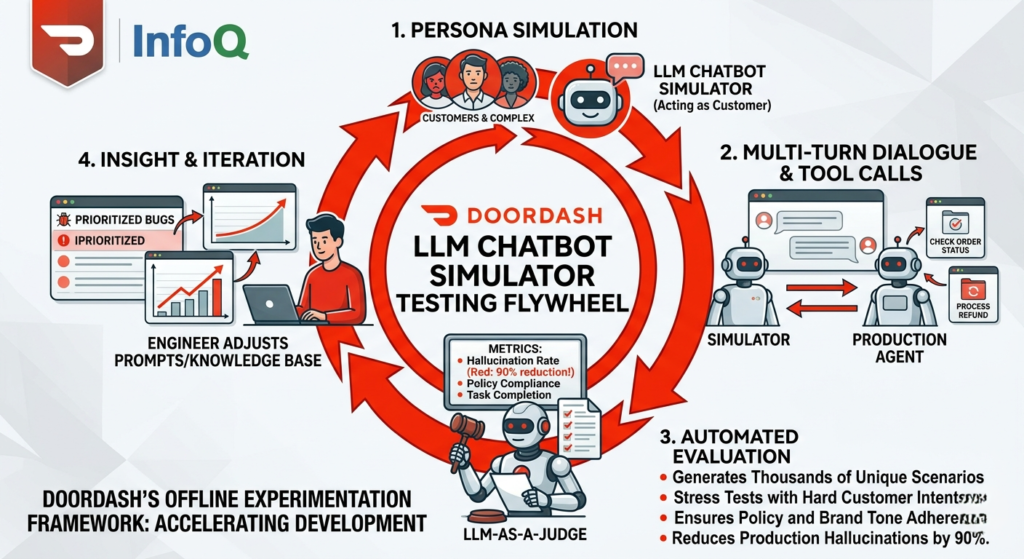
The answer lies in their latest innovation: a sophisticated LLM chatbot simulator. By building an “offline experimentation framework,” DoorDash has moved beyond manual spot-checking to a high-scale, automated “flywheel” of continuous improvement. This approach doesn’t just find bugs; it simulates the entire messiness of human interaction to ensure their AI agents are ready for the real world.
The Challenge of Testing Generative AI at Scale
When you change a single line of code in a traditional software system, you generally know what will happen. With Large Language Models (LLMs), a tiny tweak to a prompt or a slight change in the retrieval context can trigger a butterfly effect of hallucinations or tone shifts across thousands of different conversation paths.
DoorDash realized that manual review—where humans read through chat logs to find errors—simply couldn’t keep up with the pace of development. To solve this, they shifted to a model where AI tests AI. This is where the LLM chatbot simulator comes into play, acting as a tireless, “frustrated,” or “demanding” customer to stress-test the production bot before a single real user ever sees it.
How the LLM Chatbot Simulator Works
The DoorDash system isn’t just a simple script; it’s a dynamic environment that mimics the entire ecosystem of a support call. The LLM chatbot simulator acts as the “Customer” in a multi-turn dialogue, while the actual production bot acts as the “Support Agent.”
1. Extracting Real-World Personas
To make the simulations realistic, DoorDash doesn’t guess what customers sound like. They use LLMs to analyze historical support transcripts. This allows the LLM chatbot simulator to adopt specific characteristics such as:
- Customer Traits: Direct, frustrated, or demanding.
- Complex Contexts: Missing items, late deliveries, or payment issues.
- Behavioral Patterns: Pushing back against bot answers or asking for escalations.
2. Multi-Turn Dynamics
A support interaction is rarely a single question and answer. It involves a “back-and-forth” where the customer might provide new information halfway through. The LLM chatbot simulator is designed to adapt in real-time, responding to the bot’s specific answers. If the bot asks for a photo of a damaged item, the simulator provides a mock response, allowing the test to continue through the full lifecycle of the issue.
3. Backend Mocks and Tool Calls
The simulation includes “mocked” versions of DoorDash’s internal tools. This means the LLM chatbot simulator can test if the agent correctly checks delivery status, processes a refund, or identifies a Dasher’s location without needing to touch live production databases.
The “LLM-as-a-Judge” Evaluation Framework
Simulation is only half the battle; you also need a way to grade the performance. DoorDash uses an “LLM-as-a-Judge” system to automatically evaluate the results of the LLM chatbot simulator runs.
| Metric | Description | How It’s Measured |
| Hallucination Rate | Measures if the bot made up facts or policies. | Binary check against the Knowledge Base. |
| Policy Compliance | Ensures the bot follows strict legal and company rules. | Evaluator checks against predefined policy docs. |
| Task Completion | Did the user actually get their problem solved? | Analysis of the final state of the simulated conversation. |
| Tone & Sentiment | Does the bot stay professional under pressure? | Sentiment analysis of the bot’s responses to a “frustrated” simulator. |
By using the LLM chatbot simulator in tandem with these automated judges, DoorDash reduced hallucination rates by a staggering 90% before deployment.
The Development Flywheel: From Problem to Production
The most actionable insight from the DoorDash case study is their “Flywheel” workflow. This structured approach allows engineers to iterate on their AI models with the same rigor they apply to traditional software.
- Identify the Failure Mode: Engineers find a specific issue (e.g., the bot gives wrong refund info) through manual review or early LLM chatbot simulator runs.
- Build a Specific Evaluator: They create a targeted “judge” prompt to detect that specific error.
- Calibrate Against Humans: They ensure the AI judge agrees with human experts on what constitutes a “fail.”
- Run High-Scale Simulations: The LLM chatbot simulator generates hundreds of conversations focusing on that problem area.
- Adjust and Repeat: Engineers tweak the prompts or retrieval strategy and rerun the LLM chatbot simulator until the pass rate reaches an acceptable threshold.
Actionable Insights for AI Engineering Teams
If you are building your own AI agents, the DoorDash LLM chatbot simulator approach offers several high-value lessons:
- Don’t Trust One-Off Tests: A “golden set” of 10 static questions isn’t enough. You need dynamic, multi-turn simulations to catch edge cases in conversational logic.
- Structure Your Context: DoorDash found that “overloading” the context window with raw logs led to more hallucinations. They implemented a “case state layer” to structure information before feeding it to the bot.
- Focus on the “Smallest” Keyword: Notice how the LLM chatbot simulator focuses on “intent.” Don’t just simulate text; simulate the goal the user is trying to achieve.
- Automate the “Judge”: You cannot scale if a human has to read every test result. Invest early in “LLM-as-a-judge” prompts that are calibrated against your best human agents.
Conclusion
The era of “vibes-based” AI development is ending. As demonstrated by DoorDash, the future of customer service automation belongs to those who can rigorously test their models at scale. By employing an LLM chatbot simulator, DoorDash has created a safety net that allows them to innovate faster without sacrificing the user experience. Whether you are a startup or a global enterprise, adopting a simulation-first mindset is the best way to ensure your LLM agents are ready for the complexities of the real world.