The landscape of artificial intelligence shifted again on March 26, Mistral open source speech generation 2026, when Mistral AI officially launched Voxtral TTS, its groundbreaking open-source model for speech generation. This isn’t just another text-to-speech tool; it is a lightweight powerhouse capable of running locally on a smartwatch while delivering human-grade audio quality that rivals industry giants like ElevenLabs.
For developers and enterprises, the “cloud tax” on voice AI has long been a barrier to scaling. Mistral’s release changes the math entirely. By offering high-fidelity, multilingual speech synthesis under an open-weights license, they have democratized the ability to build responsive, privacy-first voice agents.
In this guide, we will dive deep into why Mistral open source speech generation is the most significant release for edge computing this year. You will learn the technical specs, explore real-world use cases, and see how it compares to proprietary alternatives.
Table of Contents
- What is Mistral Voxtral TTS?
- Key Features of the 2026 Release
- Technical Performance and Benchmarks
- Mistral vs. ElevenLabs: A Comparison
- Actionable Strategies for Implementation
- Top 10 Use Cases for Enterprise
- The Future of Multimodal Agentic Workflows
- Conclusion
<a name=”what-is-voxtral”></a>
What is Mistral Voxtral TTS?
Mistral open source speech generation refers to the Voxtral TTS model, a text-to-speech system designed for high efficiency and zero-shot voice cloning. Built on the foundation of the Ministral 3B architecture, this model is specifically optimized for “edge” deployment—meaning it can function on smartphones, laptops, and even wearables without an internet connection.
Unlike traditional TTS systems that sound robotic or require massive server clusters, Voxtral focuses on emotional intelligence and prosody. It captures the subtle nuances of human speech, including intonation, stress, and natural irregularities that make a voice feel “alive.”
<a name=”key-features”></a>
Key Features of the 2026 Release
The 2026 release of Mistral open source speech generation introduces several features that were previously exclusive to expensive, closed-source APIs.
- Zero-Shot Voice Cloning: Create a near-perfect digital twin of any voice using a sample shorter than five seconds.
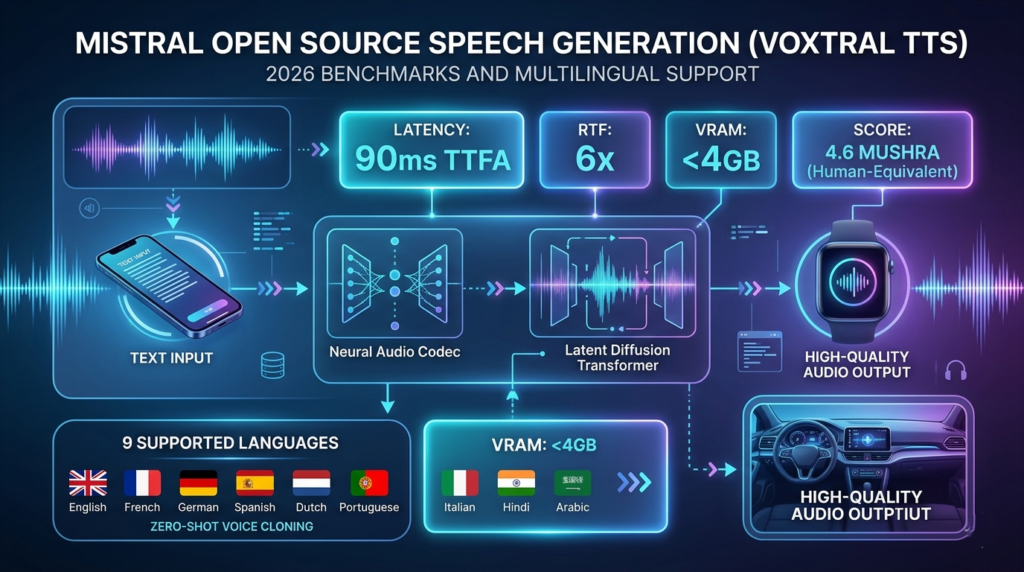
- Multilingual Mastery: Native support for 9 major languages, including English, French, German, Spanish, Dutch, Portuguese, Italian, Hindi, and Arabic.
- Low Latency (90ms): A Time-to-First-Audio (TTFA) of just 90 milliseconds, making it ideal for real-time conversational AI.
- Edge Compatibility: Optimized to run on consumer-grade hardware with minimal RAM requirements.
- Cross-Language Consistency: The model can switch languages while maintaining the unique characteristics and “soul” of the original cloned voice.
<a name=”performance”></a>
Technical Performance and Benchmarks
Efficiency is the core of the Mistral philosophy. In the voice AI space, performance is measured by two metrics: Latency and Real-Time Factor (RTF).
Mistral open source speech generation achieves an RTF of 6x. This means the model can generate 60 seconds of high-quality audio in just 10 seconds of compute time on standard hardware. For a typical 500-character sentence, users experience a delay of less than 0.1 seconds before the audio begins playing.
Key Technical Specifications:
- Base Model: Ministral 3B
- Parameter Count: Optimized for 3 Billion-class efficiency
- License: Apache 2.0 (Permissive for commercial use)
- Latency: 90ms TTFA
- Context Window: Handles long-form generation seamlessly
<a name=”comparison”></a>
Mistral vs. ElevenLabs: A Comparison
Choosing the right voice stack depends on your budget and privacy needs. Here is how Mistral open source speech generation stacks up against the current market leader.
| Feature | Mistral Voxtral TTS | ElevenLabs (Flash v2.5/v3) |
| Hosting | Local / Self-Hosted | Cloud-Only |
| Privacy | 100% Data Sovereignty | Data traverses cloud |
| Cost | Free (Compute only) | Per-character pricing |
| Voice Cloning | < 5 second sample | ~1 minute for high quality |
| Offline Mode | Yes | No |
| Customization | Full control over weights | API limited |
<a name=”strategies”></a>
Actionable Strategies for Implementation
To get the most out of Mistral open source speech generation, you should follow a tiered deployment strategy.
- Start with the Weights: Download the Voxtral weights from Hugging Face. Use the
mistral-commonlibrary to ensure compatibility with your existing Python environment. - Optimize for Quantization: If you are deploying on mobile or IoT devices, use 4-bit or 8-bit quantization to reduce the memory footprint without sacrificing significant audio quality.
- Implement Context Biasing: When using the companion Voxtral Transcribe models, provide “hint” words for technical jargon to ensure the end-to-end voice loop remains accurate.
- Leverage vLLM: For server-side deployment, use the vLLM engine to handle high-throughput requests from multiple users simultaneously.
<a name=”use-cases”></a>
Top 10 Use Cases for Enterprise
The versatility of Mistral open source speech generation makes it a “Swiss Army knife” for modern business.
- Hyper-Localized Customer Support: Build voice bots that speak regional dialects (like Hindi or Portuguese) with perfect local accents.
- Privacy-First Healthcare Assistants: Create on-device voice interfaces for patients that never send sensitive health data to the cloud.
- Automated Video Dubbing: Use the cross-language voice consistency to translate content while keeping the original speaker’s tone.
- Interactive Gaming: Generate infinite unique NPC (Non-Player Character) dialogue on the fly based on player actions.
- Smart Wearables: Enable “eyes-free” interactions on smartwatches for fitness tracking or navigation.
- Accessibility Tools: Provide high-quality, natural-sounding screen readers for the visually impaired at zero recurring cost.
- Corporate Training: Turn static PDFs into engaging, multi-speaker audio training modules automatically.
- Automotive UI: Build responsive, offline-capable voice controls for vehicle infotainment systems.
- Real-Time Translation: Pair Voxtral TTS with Mistral’s translation models for a seamless “Star Trek” style universal translator.
- Personalized Marketing: Generate custom audio messages for email campaigns using a brand-authorized “voice of the company.”
<a name=”future”></a>
The Future of Multimodal Agentic Workflows
The release of Mistral open source speech generation is a stepping stone toward a fully multimodal future. Mistral has signaled that its goal is an “end-to-end agentic system.”
In this future, an AI agent won’t just process text; it will “hear” the emotion in a user’s voice, process the intent using a model like Mistral Large 3, and “speak” back with appropriate empathy—all in one unified pipeline. This reduces the “telephone game” error rate that happens when you chain three different models together.
By moving these capabilities to the edge, Mistral is ensuring that the next generation of AI is not just powerful, but also resilient and private.
<a name=”conclusion”></a>
Conclusion
Mistral open source speech generation via Voxtral TTS represents a massive win for the open-source community. It proves that you don’t need a massive cloud infrastructure to deliver premium, human-like voice experiences. Whether you are building a global customer service platform or a simple mobile app, the barriers to entry have been permanently lowered.
The year 2026 will be remembered as the moment voice AI became truly accessible. By reclaiming control over your voice data and compute, you can build faster, cheaper, and more secure applications than ever before.