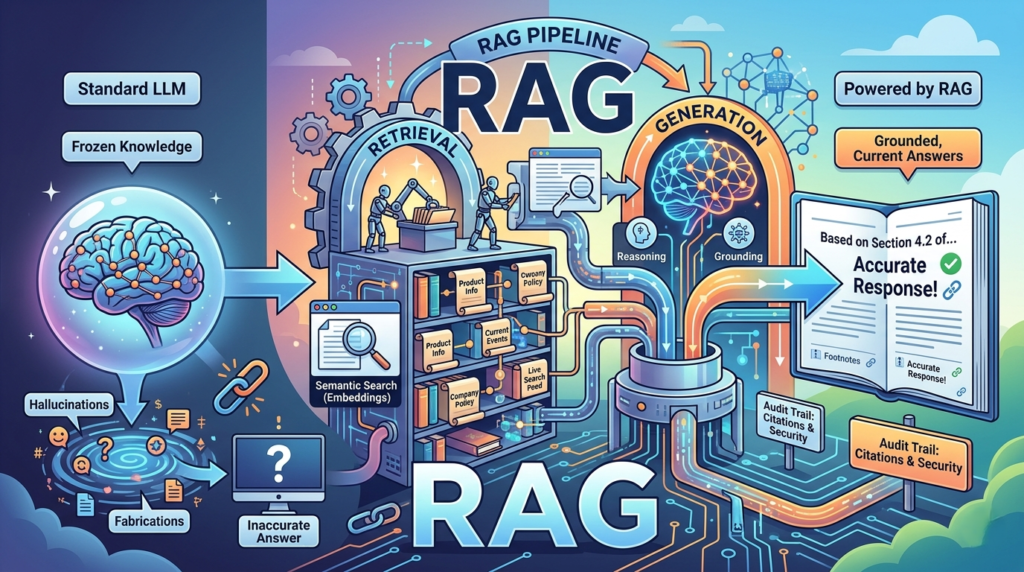
Every AI chatbot you’ve trusted has lied to you — confidently, fluently, and often. Not because it was designed to deceive, but because of a fundamental architectural flaw. Retrieval-Augmented Generation (RAG) is the engineering pattern built to fix exactly that.
If you’ve ever asked an AI about something that happened last week and received a fabricated answer presented with total confidence, you’ve witnessed the core limitation of Large Language Models (LLMs). Their knowledge is frozen at training time. They don’t know what they don’t know — so they fill the gaps. Studies show hallucination rates can be as low as 1% for simple summarization tasks, but can exceed 58% for complex, knowledge-intensive work.
RAG doesn’t patch this problem. It fundamentally rearchitects how AI accesses knowledge — and in doing so, it transforms AI from an impressive demo into a reliable production system.
This guide walks through exactly how retrieval-augmented generation works under the hood, why alternative approaches fall short, and how to think about building it correctly.
The Three Layers of the LLM Knowledge Problem
Before you can appreciate what RAG solves, you need to understand why the obvious solutions don’t work. The problem has three distinct layers.
Layer 1: LLM Knowledge Is Frozen at Training Time
Every LLM has a knowledge cutoff date. Everything the model knows was scraped, processed, and compressed into billions of numerical weights called parameters — and once training ends, that knowledge is locked. The model has no awareness of your new product launch, a critical security vulnerability disclosed this week, or the updated compliance policy your legal team published this morning.
In consumer use cases, this is an annoyance. In business contexts — customer support, legal analysis, internal search, compliance — a model that can’t access current information is a liability, not an asset.
Layer 2: Larger Context Windows Aren’t the Answer
The brute-force instinct is tempting: if the model doesn’t know something, just dump everything into the prompt. Context windows have grown dramatically — some models now support over a million tokens. But this approach has three compounding problems:
- Cost: You pay for every token. Sending your entire knowledge base with every single query will blow your budget.
- Hard limits: A million-token context window still can’t hold all the documents, databases, and communications in a large enterprise.
- Degrading accuracy: This is the one most teams discover too late. Research from Stanford and UC Berkeley shows that LLM performance follows a U-shaped curve — models perform best when key information appears at the start or end of the context, and accuracy degrades sharply when important facts are buried in the middle. In multi-document QA experiments, some models dropped to roughly 25% accuracy when the key answer was placed in the middle of a 20-document context.
More context in the prompt does not guarantee the model will use it.
Layer 3: Fine-Tuning Creates More Problems Than It Solves
Fine-tuning is when you continue training a model on your own domain-specific data, adjusting its weights to incorporate new knowledge. In theory, this teaches the model your domain. In practice, it creates a fragile, expensive snapshot.
Fine-tuning requires GPU compute, machine learning expertise, and meticulously prepared training data. It takes days or weeks to complete. And the moment your underlying data changes — a new policy, an updated product spec, a revised legal guideline — your fine-tuned model becomes stale again. The cycle restarts.
The core insight is this: what’s actually needed is providing the right information at the right time for each query, without modifying the model itself. That is precisely what retrieval-augmented generation does.
What Retrieval-Augmented Generation Actually Is
Retrieval-Augmented Generation is an architectural pattern — not a product, not a model, and not a fine-tuning technique. The concept was formalized in a 2020 paper by Patrick Lewis and his team at Facebook AI Research and University College London, which described combining a pre-trained language model’s parametric memory (the knowledge baked into its weights) with non-parametric memory (an external, updatable knowledge index accessed by a neural retriever).
The best way to understand it is through the open-book exam analogy.
A student taking a closed-book exam relies entirely on what they have memorized. That’s a standard LLM: highly capable at reasoning, but limited to what’s in its parameters. A student with an open-book exam has the same reasoning ability — but before answering, they look up the relevant pages and use that material to construct an informed, accurate response. That’s RAG.
The key distinction: you’re not changing the model. You’re changing what the model sees.
In practice, retrieval-augmented generation follows a three-step loop:
- Query — a user asks a question
- Retrieve — the system pulls the most relevant information from an external knowledge base
- Generate — the user’s question and the retrieved context go to the LLM, which produces a grounded, cited answer
You can update the knowledge by swapping the retrieval index. No retraining required.
How RAG Works Under the Hood
The three-step loop sounds simple. The engineering that makes it reliable is where things get genuinely interesting. A production-grade retrieval-augmented generation system has two main components: an offline ingestion pipeline that prepares your data, and an online retrieval pipeline that answers queries in real time.
The Foundation: Embeddings and Semantic Search
Before anything else, you need to understand embeddings — the core mechanism that makes retrieval-augmented generation work.
Text embeddings convert text into dense numerical vectors: arrays of floating-point numbers, typically with 1,536 or 3,072 dimensions, that capture meaning. The key property is that semantically similar text produces vectors that are mathematically close together in vector space — even if the words are completely different.
Consider these two questions:
- “How do I reset my password?”
- “I can’t log into my account.”
They share almost no words, but they describe the same problem. When converted to embeddings, they produce nearly identical vectors. The distance between them — measured using cosine similarity, dot product, or Euclidean distance — is tiny.
This is the fundamental insight behind RAG: the system finds relevant content by searching for meaning, not by matching keywords.
The Offline Ingestion Pipeline
Before your RAG system can answer any questions, it must process and index your entire knowledge base. This offline phase runs when new data is added, documents are updated, or a new data source is connected. It has five stages:
1. Document Loading Ingest data from anywhere: PDFs, internal databases, APIs, company wikis, Slack channels, Confluence pages. Frameworks like LangChain and LlamaIndex provide ready-made connectors for most common sources.
2. Chunking Split documents into semantically meaningful pieces. This is arguably the single highest-leverage step in the entire pipeline. Chunk too large and you lose retrieval precision. Chunk too small and you lose context. The right strategy depends on your document type — a legal brief needs different chunking than an FAQ page.
3. Embedding Generation Each chunk is converted into a vector using an embedding model. The specific model matters: the same model must be used for both ingestion and query time so that everything lives in the same vector space.
4. Vector Storage Vectors are stored in a vector database optimized for similarity search — databases like Pinecone, Weaviate, Qdrant, or pgvector. These are architected for one thing: finding the nearest neighbors of a query vector at scale, fast.
5. Metadata Tagging Each chunk is tagged with source, timestamp, category, and access control information. This metadata becomes critical for filtering (only search the HR policy documents), attribution (tell the user exactly where an answer came from), and security (don’t surface confidential data to users who shouldn’t see it).
The Online Retrieval Pipeline
When a user submits a query, the retrieval pipeline executes in real time across four stages:
1. Query Embedding The user’s question is converted into a vector using the same embedding model used during ingestion. This alignment is non-negotiable — the query and the documents must live in the same vector space.
2. Similarity Search The system finds the top-K most similar chunks by comparing the query vector against every vector in the database.
3. Retrieval Strategy This is where the real engineering decisions happen. Three primary approaches exist:
| Strategy | How It Works | Best For |
|---|---|---|
| Sparse Retrieval (BM25) | Keyword matching weighted by term frequency and inverse document frequency | Exact term matching, technical queries |
| Dense Retrieval (Embeddings) | Semantic search via vector similarity | Conceptual questions, natural language queries |
| Hybrid Search (RRF) | Combines sparse and dense results via Reciprocal Rank Fusion | Production systems requiring both precision and recall |
In most production systems, hybrid search wins — it captures the precision of keyword matching while preserving the semantic reach of vector search. Reciprocal Rank Fusion then merges the result sets by boosting documents that rank highly in both.
4. Re-Ranking After initial retrieval, a cross-encoder model rescans the top candidates. Unlike bi-encoders (which generate embeddings independently), a cross-encoder processes the query and each document as a single input — capturing fine-grained relevance signals that the embedding stage misses. This final re-ranking step separates retrieval-augmented generation systems that merely find related documents from those that find the right document.
The Generation Phase
With the most relevant chunks assembled, the system constructs the final prompt with three components:
- System Prompt — Instructions that define how the LLM should behave (e.g., “You are a helpful customer support agent for Acme Corp. Only answer based on the provided documents.”)
- Retrieved Context Chunks — The actual passages pulled from the knowledge base, inserted as grounded facts
- User’s Original Query — The exact question or task the user submitted
The LLM then reasons over the retrieved context rather than reaching into its trained memory. The response cites its sources — “Based on Section 3.2 of the Employee Handbook…” — making every answer traceable, verifiable, and auditable. This transparency is one of RAG’s most powerful advantages over any alternative.
RAG vs. the Alternatives: When to Use What
Retrieval-augmented generation isn’t the only approach to grounding AI in knowledge. Understanding the trade-offs is essential before choosing.
RAG vs. Fine-Tuning
| Dimension | RAG | Fine-Tuning |
|---|---|---|
| Knowledge updates | Swap the index — instant | Retrain the model — days/weeks |
| Cost | Inference + retrieval | GPU compute for training |
| Transparency | Citable sources | Opaque model weights |
| Expertise required | Software engineering | ML engineering |
| Best for | Factual, current, domain-specific Q&A | Style, tone, output format, behavior |
The nuance most teams miss: fine-tuning and RAG are complementary, not competing. The best production systems do both — fine-tune the model to produce a specific output format or adopt a particular persona, then use retrieval-augmented generation to fill that structure with up-to-date, accurate content.(Retrieval-Augmented Generation)
RAG vs. Long Context Windows
As context windows grow past a million tokens, a common question emerges: why not just dump everything in the prompt? The answer comes down to cost and precision.
RAG retrieves 5–20 highly relevant chunks. Long context stuffs everything in and hopes the model finds the needle. In practice:
- RAG is cheaper per query (you’re not paying for millions of tokens per request)
- RAG is more precise (the retriever does the work of finding the signal)
- RAG scales further (it can search millions of documents with no token ceiling)
That said, they work well together: use RAG to find the right 20 chunks, then use a long context window to process all of them simultaneously. The “lost in the middle” research makes a strong case that retrieving small, focused chunks outperforms massive context windows for knowledge-intensive tasks.(Retrieval-Augmented Generation)
Traditional RAG vs. Agentic RAG
The simple three-step retrieval loop works well for straightforward Q&A. But what happens when the first retrieval produces poor results? Traditional RAG pushes forward with whatever it found.(Retrieval-Augmented Generation)
Agentic RAG adds a reasoning layer on top. Instead of mechanically following a fixed pipeline, an AI agent evaluates each query and decides how to handle it:
- Reformulate the search query if initial results are weak
- Chain multiple retrieval steps for complex, multi-part questions
- Choose between different knowledge bases based on query intent
- Skip retrieval entirely when the answer is already clear
Think of it this way: Traditional RAG is a student who looks up one page and writes their answer. Agentic RAG is a student who checks multiple sources, re-reads sections that seem off, and cross-references information before putting pen to paper.(Retrieval-Augmented Generation)
The Multi-Step Production Pipeline
Production retrieval-augmented generation systems often extend the basic loop with additional intelligence at each stage:
- Query Intent Parsing — Before searching, analyze what the user actually wants. Is it a factual lookup? A comparison? A summary? Intent determines the optimal retrieval strategy and which knowledge base to query.
- Query Reformulation — Rewrite the user’s question to improve retrieval quality. “Why is my app slow?” might become “application performance bottleneck causes and solutions” — a query more likely to surface useful technical documentation.
- Retrieval — Execute the hybrid search with re-ranking, as described above.
- Live Web Search Augmentation — Some RAG systems can fall back to live web search when internal documents are insufficient for current information.
- Re-ranking and Filtering — Score, deduplicate, and filter the results for relevance and access permissions.
- Grounded Generation — The LLM produces a cited, attributable answer grounded in all gathered context.
This multi-step architecture is what separates a RAG demo from a RAG production system. The difference is not just performance — it’s reliability, trust, and the ability to audit every answer.
Key Takeaways: What Makes RAG Powerful
Retrieval-augmented generation has become the dominant architectural pattern for enterprise AI for concrete reasons:(Retrieval-Augmented Generation)
- Knowledge stays current — Update the index, not the model. Changes take effect immediately.
- Answers are traceable — Every claim links back to a source document. No black box.
- Hallucinations are reduced — The model reasons over facts you provide, not fabricated memories.
- Cost scales efficiently — You retrieve what’s needed, not everything.
- Security is enforceable — Metadata filtering ensures users only see content they’re authorized to access.
- No ML expertise required — RAG is a software engineering problem, not a machine learning research problem.
The architectural elegance of RAG is in its simplicity: you’re not trying to make the model smarter. You’re making sure it has the right information, at the right time, for every single query.(Retrieval-Augmented Generation)
Building RAG: Practical Starting Points
If you’re ready to implement retrieval-augmented generation in your own systems, here are the most important practical decisions:(Retrieval-Augmented Generation)
Chunking strategy — Invest time here. Fixed-size chunking is easy but often wrong. Semantic chunking, where you split on natural boundaries like paragraphs or sections, typically produces better retrieval results. For structured documents like legal contracts or technical specs, consider hierarchical chunking.
Embedding model selection — OpenAI’s text-embedding-3-large, Cohere’s Embed v3, and open-source alternatives like BGE or E5 are all strong options. Evaluate on your specific domain — embedding quality varies significantly by content type.
Vector database — For small-to-medium scale, pgvector (Postgres extension) reduces operational complexity. For production at scale, Pinecone, Qdrant, or Weaviate offer purpose-built performance.
Re-ranking — Don’t skip this step. Cohere Rerank and cross-encoders like BGE Reranker consistently improve answer quality with minimal added latency.(Retrieval-Augmented Generation)
Evaluation — Build evaluation into your pipeline from day one. RAGAs is a popular open-source framework for measuring retrieval precision, answer faithfulness, and context relevance. Without measurement, you’re flying blind.(Retrieval-Augmented Generation)
Final Thoughts
Retrieval-augmented generation is not a silver bullet — no architecture is. It has genuine limitations around retrieval quality, latency, and the cost of maintaining high-quality knowledge bases. But it represents the most practical, production-ready solution currently available for grounding LLMs in accurate, current, domain-specific knowledge.
The teams building reliable AI products today are not betting on bigger models or infinite context windows. They’re building better retrieval pipelines.
Understanding how retrieval-augmented generation works — not just what it is, but why each step exists — is now a core competency for any engineer or architect building AI systems.