In the rapidly evolving landscape of artificial intelligence, the ability for machines to “see” and “describe” simultaneously has become the new frontier. We are no longer limited to text-only interactions; we are entering the era of multimodal intelligence. If you’ve ever wondered how a standard LLM transforms into a vision-capable powerhouse, you’re in the right place.
This guide breaks down the complex architecture of Vision-Language Models and provides a technical roadmap for building these systems from the ground up. Whether you are an AI researcher or a curious developer, understanding how Vision-Language Models are constructed is essential for the next generation of AI applications.
What is a Vision-Language Model?
At its core, a Vision-Language Model (VLM) is a multimodal system designed to process and relate information from two distinct modalities: images and text. While a traditional Large Language Model (LLM) like GPT-4 is a master of text, a Vision-Language Model bridges the gap by “grounding” visual data into a linguistic context.
To achieve this, the architecture typically relies on three fundamental pillars:
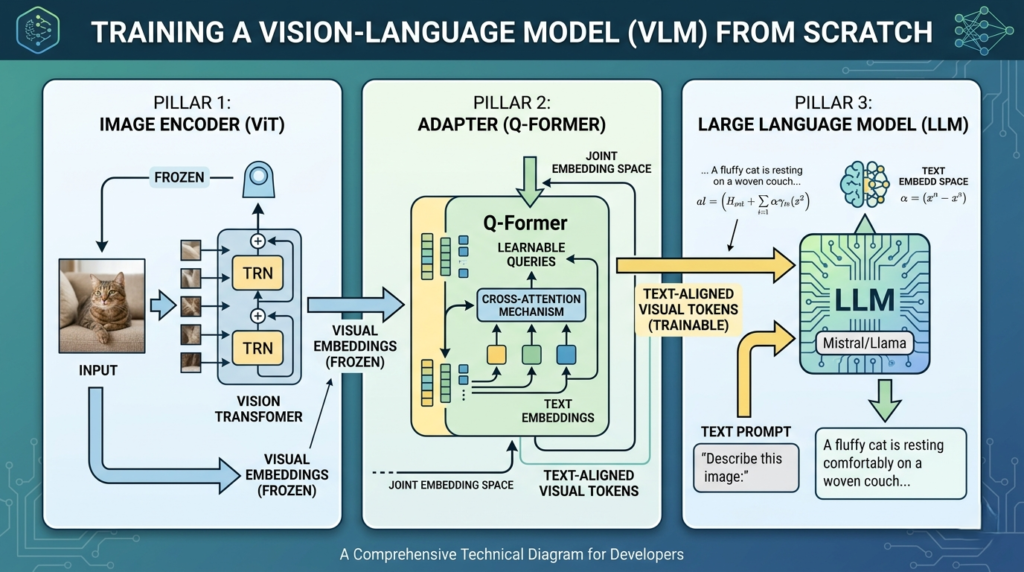
- The Image Backbone: A dedicated module that extracts features from raw pixels.
- The Adapter Layer: The “bridge” that translates visual features into a language the LLM understands.
- The Language Layer: The core engine that processes the combined data to generate human-like responses.
The 3 Pillars of VLM Architecture
Building a Vision-Language Model isn’t just about sticking a camera onto a chatbot. It requires a sophisticated alignment of vector spaces. Let’s look at the mechanics behind each component.
1. The Image Backbone (The Eyes)
Modern Vision-Language Models have largely shifted away from traditional Convolutional Neural Networks (CNNs) in favor of Vision Transformers (ViTs). ViTs treat an image as a sequence of patches—much like a language model treats text as a sequence of tokens.
- Input: Raw pixel maps.
- Output: A sequence of vector embeddings representing visual features.
- Pro Tip: Most developers use a “frozen” (non-trainable) pre-trained ViT to save on massive computational costs while retaining high-quality feature extraction.
2. The Adapter Layer (The Translator)
This is where the magic happens. The embeddings from a ViT are “text-unaware.” They represent shapes and colors, but they don’t know the word “cat.” The Adapter Layer—often implemented as a Q-Former (Query Transformer)—grounds these pixels into text-compatible embeddings.
By using cross-attention mechanisms, the adapter allows the model to map visual “tokens” into the same high-dimensional space as textual “tokens.”
3. The Language Layer (The Brain)
The final stage of a Vision-Language Model involves feeding these adapted visual tokens into a pre-trained LLM. The language model views these visual inputs as just another part of the prompt, allowing it to reason about the image and generate descriptive text.
How Vision-Language Models Are Trained: The Step-by-Step Recipe
Training Vision-Language Models from scratch typically follows a specialized pipeline to ensure the vision and language components are perfectly aligned.
Phase 1: Pre-training the Multi-modal Space
In this phase, the goal is to create a “joint embedding space” where images and their corresponding captions are mathematically close to each other.
- Contrastive Learning: Using a loss function (like CLIP), the model learns to minimize the distance between a “dog” image and the word “dog,” while maximizing the distance from unrelated words like “airplane.”
- Image-Text Matching (ITM): The model predicts whether a specific caption accurately describes a given image.
Phase 2: Supervised Fine-Tuning (SFT)
Once the model understands general relationships, we fine-tune the Vision-Language Model on specific instruction datasets (e.g., LLaVA-Instruct). This teaches the model to follow complex commands like “Describe the emotion of the person in this photo” rather than just providing simple captions.
Comparison: VLM Component Strategies
When designing your Vision-Language Model, the choice of architecture significantly impacts performance and cost.
| Component | Popular Choice | Why it’s used | Status during training |
| Image Encoder | ViT-L/14 (CLIP) | Superior scaling and multimodal alignment | Usually Frozen |
| Adapter | Q-Former / MLP | Efficiently maps vision to text dimensions | Trainable |
| Language Model | Llama 3 / Mistral | High-reasoning capabilities | Frozen or LoRA-tuned |
Key Challenges in VLM Development
Even though the blueprint for a Vision-Language Model is clear, several hurdles remain for developers:
- Hallucination: Unlike text-only models, a Vision-Language Model might “see” objects that aren’t there if the alignment isn’t perfect.
- Spatial Reasoning: Many models struggle with concepts like “left of” or “behind” without specific spatial training data.
- Computational Weight: Training these models from absolute zero requires thousands of GPU hours. Using pre-trained backbones is the standard industry workaround.
Actionable Insights for AI Engineers
If you are looking to implement a Vision-Language Model today, keep these three tips in mind:
- Leverage Frozen Backbones: Don’t try to train a ViT and an LLM from scratch simultaneously. Focus your “compute budget” on the Adapter Layer (the projector).
- Quality Over Quantity for Data: 50,000 high-quality, dense image descriptions are often better than 5 million noisy, automated web-scraped captions.
- Use Modern Toolkits: Libraries like Hugging Face
TRL(Transformer Reinforcement Learning) andSFTTrainerhave built-in support for VLM fine-tuning, making the process much more accessible.
The Future of Vision-Language Models
The trajectory of Vision-Language Models is moving toward “Any-to-Any” multimodality—models that can not only see and speak but also hear and generate video. By mastering the fundamental architecture of the Vision-Language Model now, you are preparing for a future where AI perceives the world exactly as we do.
Training a Vision-Language Model is no longer a “black box” operation reserved for big tech. With the right alignment strategy and a solid understanding of adapters, anyone can begin building vision-capable agents.