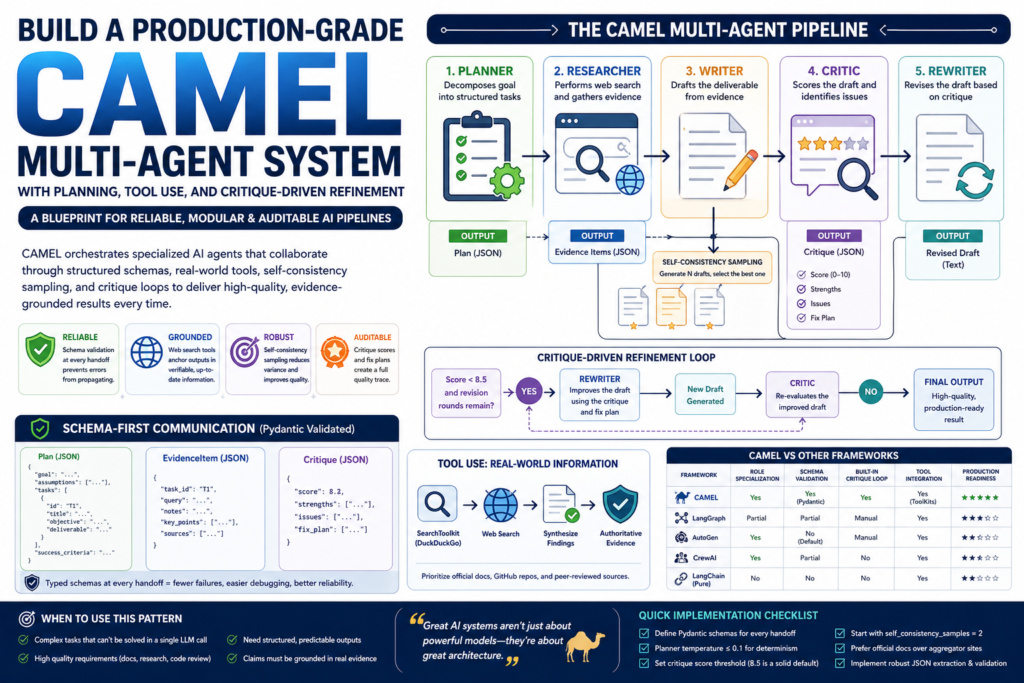
If you want to move beyond toy AI demos and into reliable, real-world agentic pipelines, the CAMEL multi-agent system gives you a battle-tested blueprint — one that combines structured planning, web-grounded research, self-consistency sampling, and iterative critique into a single coherent workflow.
This guide breaks down exactly how that architecture works, why each component matters, and how you can implement it yourself — whether you’re an ML engineer prototyping your first agent pipeline or a team lead evaluating frameworks for production.
What Is a CAMEL Multi-Agent System?
CAMEL (Communicative Agents for “Mind” Exploration of Large Language Model Society) is an open-source agentic AI framework designed to orchestrate multiple LLM-powered agents that collaborate to solve complex tasks. Rather than relying on a single monolithic prompt, a CAMEL multi-agent system assigns distinct roles — planner, researcher, writer, critic, rewriter — each with a clearly scoped responsibility and a structured communication protocol.
Think of it like a well-run editorial team: one person outlines the story, another gathers facts, a third writes the draft, a fourth tears it apart, and a fifth refines it. The difference is that every “team member” here is an LLM agent operating on validated, typed data.
Why does this matter? Because most AI pipelines fail not due to model capability, but due to architectural fragility — unvalidated outputs, hallucinated citations, and no mechanism for self-correction. The CAMEL multi-agent system solves all three.
Why Production-Grade Design Matters
The Gap Between Prototypes and Real Systems
A single-agent system asking GPT-4 a complex research question might return a plausible-sounding answer 70% of the time. In production, that 30% failure rate is unacceptable. Production-grade agentic systems need:
- Deterministic output schemas so downstream components don’t break
- Tool use so agents can access real, current information
- Quality feedback loops that catch errors before they propagate
- Modular architecture so individual agents can be swapped or upgraded independently
The CAMEL multi-agent system addresses every one of these requirements through deliberate architectural choices, not workarounds.
Core Architecture of the Pipeline
The Five Specialized Agents
A production CAMEL multi-agent system is built around five agents, each laser-focused on one stage of the workflow:
| Agent | Role | Output Type |
|---|---|---|
| Planner | Decomposes the goal into structured tasks | JSON (Plan schema) |
| Researcher | Performs web searches and synthesizes evidence | JSON (EvidenceItem schema) |
| Writer | Drafts the deliverable from evidence | Plain text |
| Critic | Scores the draft and identifies weaknesses | JSON (Critique schema) |
| Rewriter | Revises the draft based on critique | Plain text |
Each agent is initialized with a system prompt that enforces its role boundaries and output format. This tight scoping is what makes the CAMEL multi-agent system genuinely modular — you can replace the researcher with a domain-specific tool or swap the writer’s model without touching any other component.
Pydantic-Validated Communication
One of the most underrated features of a well-designed CAMEL multi-agent system is schema validation at every handoff. Rather than passing raw strings between agents, every structured output is validated against a Pydantic model:
Plan— contains goal, assumptions, a list ofPlanTaskobjects, and success criteriaEvidenceItem— contains query, notes, and key pointsCritique— contains a 0–10 score, strengths, issues, and a fix plan
This means if an agent returns malformed JSON or omits a required field, the pipeline fails loudly at the boundary — not silently downstream in a corrupted output. For production systems, this is non-negotiable.
Planning Phase — Structured Goal Decomposition
What does the planner do? It takes a high-level goal and returns a structured Plan object — a breakdown of up to five concrete tasks, each with an objective, expected deliverable, tool hints, and potential risks.
The planner uses a very low temperature (0.1) to maximize determinism. It’s not creative; it’s analytical. Its only job is to transform an ambiguous goal into a machine-readable action plan that every downstream agent can reference.
Here’s what a well-formed plan task looks like in the CAMEL framework:
json
{
"id": "T1",
"title": "Survey CAMEL core abstractions",
"objective": "Identify ChatAgent, RolePlaying, and ToolKit primitives",
"deliverable": "Concise notes on architecture and key APIs",
"tool_hints": ["search CAMEL GitHub docs"],
"risks": ["Documentation may be outdated"]
}This level of explicitness is what separates a production planning agent from a vague chain-of-thought prompt.
Research Phase — Tool Use and Grounded Evidence
How does the researcher avoid hallucinating facts? By actually using tools — specifically web search — rather than generating text from memory.
In the CAMEL multi-agent system, the researcher agent is initialized with access to SearchToolkit().search_duckduckgo. For each task in the plan, it:
- Identifies the most relevant search query
- Executes up to a configured maximum of web searches (e.g., 2 per task)
- Synthesizes findings into an
EvidenceItem— structured notes plus key points
The key architectural decision here is that the researcher is instructed to prioritize authoritative sources — official documentation, GitHub repositories, peer-reviewed work — before falling back to secondary sources. And critically, if evidence is thin, the system is designed to acknowledge uncertainty rather than fabricate.
This grounding step is what makes the CAMEL multi-agent system suitable for research-heavy tasks like technical brief generation, competitive analysis, or due diligence — domains where hallucinated facts carry real cost.
Self-Consistency Sampling — Drafting for Robustness
What is self-consistency sampling? It is the practice of generating multiple independent outputs for the same input and selecting the best one — originally developed in the context of chain-of-thought reasoning, but equally valuable for open-ended text generation.
In this pipeline, the writer agent produces n independent drafts (configured via self_consistency_samples, defaulting to 2). A dedicated selector agent — initialized with temperature 0.0 for maximum determinism — then evaluates all candidates and returns the single best draft, unchanged.
This approach yields measurable quality improvements because:
- Variance reduction: Rare model failures on one sample don’t survive to the final output
- Coverage increase: Different drafts may emphasize different aspects; the best one captures the most complete picture
- Ensemble-like robustness: No single-point-of-failure in the generation step
Self-consistency is one of the most cost-effective quality improvements you can add to any agentic AI framework — it requires no fine-tuning, no additional tooling, and only marginal inference cost.
Critique-Driven Refinement — The Quality Control Loop
What makes critique-driven refinement different from just prompting better? The feedback is structured, scored, and actionable — not just a vague “make it better” instruction.
Here’s how the critique-and-revision loop works in the CAMEL multi-agent system:
- The critic agent receives the draft and the original goal
- It returns a
Critiqueobject with a numeric score (0–10), a list of strengths, a list of issues, and a concrete fix plan - If the score is below 8.5 and revision rounds remain, the rewriter agent receives the draft plus the full critique and produces an improved version
- The loop continues until the quality threshold is met or the maximum revision rounds are exhausted
Critique (Round 1) → score: 7.2/10
Issues: ["Missing concrete code example", "Abstract section too vague"]
Fix plan: ["Add working snippet for ChatAgent init", "Define 'abstraction' with a one-line example"]
Rewriter → produces improved draft
Critique (Round 2) → score: 8.9/10 → pipeline exitsThis architecture mirrors how human editorial review works — and crucially, it’s automatic and auditable. Every critique score and fix plan is logged, giving you a quality trace for every output your system produces.
CAMEL vs Other Multi-Agent Frameworks
How does the CAMEL multi-agent system compare to alternatives you might consider for a similar agentic pipeline?
| Framework | Role Specialization | Schema Validation | Built-in Critique Loop | Tool Integration | Production Readiness |
|---|---|---|---|---|---|
| CAMEL | Yes (per-agent roles) | Yes (Pydantic) | Yes (built-in critic) | Yes (ToolKits) | High |
| LangGraph | Partial (node-based) | Partial | Manual | Yes | High |
| AutoGen | Yes (conversation-style) | No (by default) | Manual | Yes | Medium-High |
| CrewAI | Yes (crew roles) | Partial | No | Yes | Medium |
| Pure LangChain | No | No | No | Yes | Low-Medium |
Key takeaway: CAMEL’s differentiation is the combination of role specialization, enforced schema contracts, and a native critique-refinement loop in a single framework. LangGraph offers comparable production readiness but requires more custom orchestration code to achieve the same structured output guarantees.
Key Takeaways and When to Use This Pattern
What the CAMEL multi-agent system gets right
- Modularity: Each agent can be independently upgraded, monitored, or replaced
- Traceability: Pydantic schemas create an audit trail at every stage
- Reliability: Self-consistency sampling + critique loops reduce both variance and systematic errors
- Groundedness: Tool use anchors outputs in verifiable evidence rather than parametric memory
When to use a CAMEL multi-agent system
This architecture is the right choice when your task has all of the following properties:
- Complexity — it can’t be reliably solved in a single LLM call
- Quality requirements — errors are costly (technical documentation, research, code review)
- Structured outputs — downstream systems need predictable, typed data
- Evidence dependence — claims should be grounded in retrieved information, not generated
When it may be overkill
- Simple Q&A or single-turn tasks
- Latency-sensitive applications where multiple LLM calls are prohibitive
- Tasks where schema design overhead outweighs the quality gains
Quick implementation checklist
- Define Pydantic schemas for every inter-agent handoff before writing any agent code
- Set planner temperature to ≤0.1 for maximum determinism
- Configure a minimum critique score threshold (8.5 is a solid default)
- Start with
self_consistency_samples=2; increase if quality is insufficient and cost allows - Always instruct research agents to prefer official documentation over aggregator sites
- Implement
extract_first_json_object()or equivalent to robustly parse LLM JSON output
Frequently Asked Questions
Q: Does a CAMEL multi-agent system require GPT-4? No. CAMEL’s ModelFactory supports multiple platforms including OpenAI, Anthropic, and open-weight models. GPT-4o is used in the reference implementation for its JSON instruction-following reliability, but other capable models work too.
Q: How many revision rounds should I configure? Start with 1–2. Beyond 3 rounds, quality gains diminish and cost increases significantly. Set a score threshold (e.g., 8.5/10) to exit early when quality is already high.
Q: Can I add more agents to the pipeline? Yes — and that’s one of CAMEL’s strengths. You could add a fact-checker agent, a summarizer, or a formatter without restructuring the existing pipeline, as long as each new agent has a defined schema contract.
Q: What’s the biggest failure mode to watch for? JSON extraction fragility. LLMs sometimes wrap JSON in markdown code fences or add preamble text. Always implement a robust JSON extraction utility (like extract_first_json_object()) and validate against your Pydantic schema with a try/except fallback.
Conclusion
Building a production-grade CAMEL multi-agent system is about much more than chaining a few LLM calls together. It demands deliberate architectural choices: Pydantic schemas to enforce contracts, specialized agents with tight role boundaries, tool use to ground claims in reality, self-consistency to reduce variance, and a critique loop to enforce quality before any output leaves the pipeline.
The result is an agentic AI framework that is not just capable — it’s auditable, modular, and genuinely production-ready. Whether you’re building technical brief generators, research assistants, or automated code review tools, this pattern gives you the structural foundation to ship AI systems that work reliably in the real world.