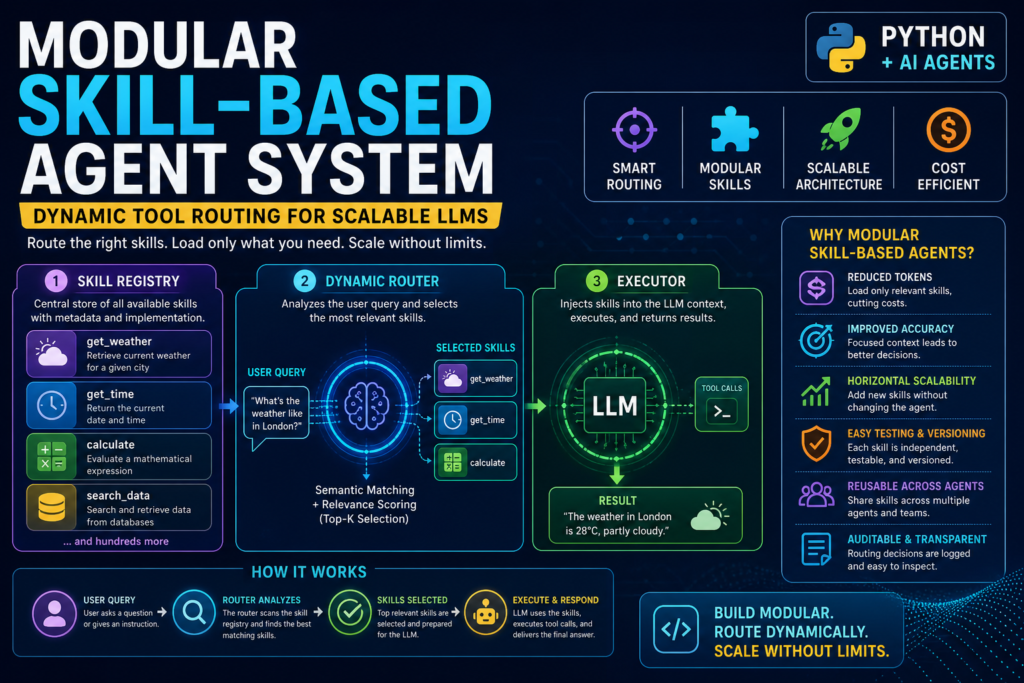
A modular skill-based agent system lets LLMs call only the tools they need — when they need them. If you’re tired of bloated prompts, token overflows, and agents that can’t scale past a handful of tools, this architecture is the answer. By combining a structured skill registry with dynamic tool routing, you can build Python-based LLM agents that are fast, extensible, and production-ready.
What Is a Modular Skill-Based Agent System?
Definition
A modular skill-based agent system is an LLM architecture where capabilities are packaged into discrete, self-contained “skills” — each representing a specific tool, procedure, or workflow — and loaded into the agent’s context only when relevant to a given task.
Think of it as the difference between handing an employee every manual in the company versus routing them to only the manuals they need for today’s job. The latter is faster, cheaper, and more accurate.
How It Differs from Traditional Tool Use
Traditional LLM tool use (function calling) works by passing a flat list of available tools to the model on every request. This approach breaks down at scale. When a skill ecosystem grows to hundreds or thousands of entries, presenting every option at inference time is computationally infeasible and semantically noisy.
A modular skill-based agent system solves this with a two-stage process:
- Skill routing — identify which skills are relevant to the user’s task.
- Skill injection — load only those skills into the agent’s context before execution.
This is the core insight behind systems like Claude Code, which exposes reusable skills as a first-class capability in its agentic architecture.
The Three-Paradigm Evolution of LLM Capability
Understanding where skill-based systems sit in the broader LLM landscape helps you appreciate why this architecture matters now.
According to recent research on agent skill architectures, the evolution of LLM capability extension follows three distinct phases:
Paradigm 1 — Prompt Engineering (2022–2023) Carefully crafted instructions elicit zero-shot and few-shot behaviors. But prompts are ephemeral, non-modular, and difficult to version or share at scale.
Paradigm 2 — Tool Use and Function Calling (2023–2024) Models can invoke external APIs. Each tool is atomic — a single function with defined inputs and outputs. Tools execute and return; they don’t reshape the agent’s understanding of a task or carry procedural context.
Paradigm 3 — Skill Engineering (2025–present) A skill is a bundle that can include instructions, workflow guidance, executable scripts, reference documentation, and metadata — all organized to be dynamically loaded when relevant. The key insight is that many real-world tasks require not a single tool call but a coordinated sequence of decisions informed by domain-specific procedural knowledge.
A modular skill-based agent system is the practical implementation of Paradigm 3.
Core Architecture of a Modular Skill-Based Agent System
Every well-designed modular skill-based agent system has three components working in concert.
1. The Skill Registry
The skill registry is a structured store of all available capabilities. Each entry contains:
- A unique skill ID and name
- A natural language description (used for routing)
- The full implementation body (loaded only when the skill is selected)
- Metadata (category, version, dependencies)
The registry is intentionally asymmetric: the routing component can inspect full skill text, while the agent that eventually consumes the skill usually sees only its name and description. This “progressive disclosure” pattern keeps the context window lean.
2. The Dynamic Router
The dynamic router is the intelligence layer. Given a user task, it queries the registry and returns a shortlist of relevant skills. Routing strategies range from simple keyword matching to dense vector retrieval using embeddings.
This is the highest-leverage component in the system. If the wrong skill shortlist is surfaced, downstream planning and execution will fail regardless of how capable the base LLM is.
3. The Executor
The executor takes the shortlisted skills, injects them into the agent’s prompt or context, and runs the LLM to completion. The executor also handles tool call parsing, error recovery, and result formatting.
Building a Modular Skill-Based Agent System Step by Step in Python
Let’s translate this architecture into working code. We’ll use Python with a dictionary-based registry and semantic similarity for routing.
Step 1: Define the Skill Schema
python
from dataclasses import dataclass, field
from typing import Callable, Optional
@dataclass
class Skill:
skill_id: str
name: str
description: str # Used for routing (short, semantic)
execute: Callable # The actual function
category: str = "general"
keywords: list[str] = field(default_factory=list)Each skill is a self-contained unit. The description field is what the router reads; execute is what the executor calls.
Step 2: Build the Skill Registry
python
class SkillRegistry:
def __init__(self):
self._skills: dict[str, Skill] = {}
def register(self, skill: Skill):
self._skills[skill.skill_id] = skill
def list_all(self) -> list[Skill]:
return list(self._skills.values())
def get(self, skill_id: str) -> Optional[Skill]:
return self._skills.get(skill_id)Step 3: Implement Dynamic Tool Routing
Here’s a keyword-overlap router — simple, deterministic, and a great starting point:
python
def route_skills(query: str, registry: SkillRegistry, top_k: int = 3) -> list[Skill]:
query_tokens = set(query.lower().split())
scored = []
for skill in registry.list_all():
desc_tokens = set(skill.description.lower().split())
kw_tokens = set(kw.lower() for kw in skill.keywords)
overlap = len(query_tokens & (desc_tokens | kw_tokens))
if overlap > 0:
scored.append((overlap, skill))
scored.sort(key=lambda x: x[0], reverse=True)
return [skill for _, skill in scored[:top_k]]For production systems, replace token overlap with embedding-based cosine similarity using a model like text-embedding-3-small from OpenAI or a local SentenceTransformer.
Step 4: Register Skills
python
import datetime
registry = SkillRegistry()
registry.register(Skill(
skill_id="get_weather",
name="Get Weather",
description="Retrieve current weather conditions for a given city",
execute=lambda city: f"Weather in {city}: 28°C, partly cloudy",
keywords=["weather", "temperature", "forecast", "climate"]
))
registry.register(Skill(
skill_id="get_time",
name="Get Current Time",
description="Return the current date and time",
execute=lambda: datetime.datetime.now().strftime("%Y-%m-%d %H:%M:%S"),
keywords=["time", "date", "clock", "now"]
))
registry.register(Skill(
skill_id="calculate",
name="Calculator",
description="Evaluate a mathematical expression and return the result",
execute=lambda expr: str(eval(expr)), # Use ast.literal_eval in production
keywords=["math", "calculate", "compute", "arithmetic", "formula"]
))Step 5: Build the Agent Executor
python
def run_agent(user_query: str, registry: SkillRegistry):
# Step 1: Route
matched_skills = route_skills(user_query, registry)
if not matched_skills:
return "No relevant skills found for this query."
# Step 2: Build skill context
skill_context = "\n".join([
f"- [{s.skill_id}] {s.name}: {s.description}"
for s in matched_skills
])
# Step 3: Construct prompt for LLM
prompt = f"""You are a helpful assistant with access to the following skills:
{skill_context}
User query: {user_query}
Respond by choosing the most appropriate skill and calling it.
Format: CALL skill_id WITH args"""
# Step 4: (Simulate LLM response for demo)
# In production, send `prompt` to your LLM API
print(f"[Router] Matched skills: {[s.skill_id for s in matched_skills]}")
print(f"[Prompt sent to LLM]:\n{prompt}")
# Example usage
run_agent("What's the weather like in London?", registry)This is the minimal viable modular skill-based agent system. From here, you can layer in embedding-based routing, multi-step planning, error retry logic, and skill versioning.
Dynamic Tool Routing Strategies Compared
Choosing the right routing strategy is critical. Here’s a comparison of the most common approaches:
| Routing Strategy | How It Works | Best For | Limitations |
|---|---|---|---|
| Keyword Overlap | Matches query tokens against skill descriptions and keyword tags | Prototyping, low-latency needs | Fails on synonyms and paraphrase |
| Embedding Similarity | Encodes query and skills as vectors; retrieves top-k by cosine distance | Production systems with large skill sets | Requires embedding model, higher latency |
| LLM-as-Router | Sends skill names/descriptions to an LLM to select the best match | Complex, ambiguous queries | Expensive; adds one full LLM call |
| BM25 / TF-IDF | Sparse retrieval over skill descriptions | Keyword-heavy domains, interpretable ranking | Less effective for semantic paraphrase |
| Hybrid (Sparse + Dense) | Combines BM25 with embedding similarity via re-ranking | Best overall accuracy at scale | Most complex to implement |
| Rule-Based / Intent Classifier | Pre-trained classifier maps intents to skill categories | High-precision, narrow domains | Requires labeled training data |
For most production deployments, a hybrid sparse-dense approach delivers the best accuracy-latency tradeoff. Start with keyword overlap for your MVP, then graduate to embedding similarity as your skill library grows past 20–30 entries.
Key Benefits of a Modular Skill-Based Agent System
A well-implemented modular skill-based agent system delivers measurable advantages over monolithic approaches:
- Reduced token consumption — only relevant skills occupy context, dramatically cutting costs in API-billed environments.
- Improved accuracy — focused context means the LLM faces fewer irrelevant options, reducing hallucination and wrong tool selection.
- Horizontal scalability — adding a new skill to the registry doesn’t require rewriting the agent; the router handles discovery automatically.
- Easier testing and versioning — each skill is a discrete unit that can be tested, updated, and rolled back independently.
- Progressive disclosure — the router filters at inference time, so the agent never sees skill implementations it doesn’t need, protecting IP and reducing prompt complexity.
- Cross-agent reuse — skills registered once can be shared across multiple agents in a multi-agent system without duplication.
- Auditability — the routing decision (which skills were selected and why) is a logged, inspectable step, supporting debugging and compliance.
Common Mistakes to Avoid
Even experienced engineers make these errors when building a modular skill-based agent system for the first time.
Mistake 1: Using Vague Skill Descriptions
The description field is what the router reads. Descriptions like “does data stuff” or “helper function” produce poor routing. Every description should follow a consistent pattern: [Verb] + [Object] + [Context]. For example: “Retrieve current stock price for a given ticker symbol from financial APIs.”
Mistake 2: Monolithic Skills
A skill that does five different things is not modular — it’s a function dressed up as a skill. If a skill’s description requires the word “and” more than once, split it. Atomic skills route better and fail more gracefully.
Mistake 3: Skipping the Registry Abstraction
It’s tempting to hardcode a list of skills directly into the router. Resist this. Without a proper registry, adding new skills requires touching routing logic, which defeats the purpose of a modular skill-based agent system. The registry is the interface contract.
Mistake 4: Using Only One Routing Signal
Top-k by similarity alone can miss the mark. Combine relevance score with skill category filters (e.g., only surface financial skills for finance-domain queries) to sharpen routing precision without sacrificing recall.
Mistake 5: No Fallback Strategy
What happens when the router returns zero matches? Every agent needs a default path — either a general-purpose skill, a clarification prompt to the user, or a graceful “I can’t help with that” response. Silent failure erodes user trust quickly.
When Should You Use This Architecture?
A modular skill-based agent system is the right choice when:
- Your agent needs access to more than 10–15 tools, making full-context injection impractical.
- You’re building in a multi-tenant or enterprise environment where different users or teams need different skill subsets.
- You need explainability — stakeholders want to know which tool was selected and why.
- You’re running in a cost-sensitive environment where token usage is directly billed.
- You anticipate ongoing skill additions and want to avoid re-engineering the agent with every new capability.
Simpler single-purpose agents with a small, stable toolset don’t necessarily need a full skill registry. But any system aiming for production scale and longevity will benefit from the modular approach.
Modular Skill-Based Agent Systems vs. Traditional Approaches: A Summary
To ground the comparison, here is a side-by-side view of a traditional monolithic agent versus a modular skill-based agent system:
| Dimension | Traditional Monolithic Agent | Modular Skill-Based Agent System |
|---|---|---|
| Context loading | All tools, every request | Only relevant skills, per request |
| Scalability | Degrades past ~15 tools | Scales to thousands of skills |
| Cost | High (large prompt always) | Low (minimal context injection) |
| Routing | None (LLM sees everything) | Explicit routing layer |
| Skill reuse | Not supported | Native via shared registry |
| Debugging | Hard (opaque selection) | Easy (routing step is logged) |
| Skill updates | Requires prompt rewrite | Update registry entry only |
Conclusion: The Future of LLM Agent Design Is Modular
The era of passing a flat list of tools to an LLM on every request is ending. As skill ecosystems grow and enterprise deployments demand scalability, reliability, and cost efficiency, the modular skill-based agent system has emerged as the foundational pattern for production-grade LLM agents.
The architecture is straightforward to implement in Python — a schema-driven registry, a routing layer, and an executor — but its impact compounds as your system grows. Every new skill you register makes the agent more capable without increasing the cognitive load on the underlying model.
Start with keyword-based routing and a small registry. Graduate to embedding similarity. Add hybrid routing as your library scales. The pattern remains the same at every stage; only the sophistication of the router changes.
Build modular. Route dynamically. Scale without limits.
Frequently Asked Questions
What is dynamic tool routing in LLM agents? Dynamic tool routing is the process of selecting which skills or tools to inject into an LLM agent’s context at inference time, based on the specific user query, rather than loading all available tools on every request.
How many skills can a modular skill-based agent system handle? With embedding-based routing, systems have been demonstrated to scale effectively to tens of thousands of skills. The routing step filters this down to a small, relevant shortlist before the LLM ever sees them.
Is a modular skill-based agent system the same as a RAG pipeline? They share the retrieval concept, but differ in what is retrieved. RAG retrieves documents or knowledge chunks. A skill-based agent system retrieves executable procedures, workflow guidance, and tool affordances — content that shapes how the agent acts, not just what it knows.
What Python frameworks support skill-based agent architectures? LangChain, LlamaIndex, Haystack, and AutoGen all provide building blocks for modular agent systems, though none enforces the full skill registry + routing pattern out of the box. The implementation above gives you direct control over every layer.