Perplexity Brain is not another chatbot memory that remembers your name and favorite topics. It is a fundamentally different class of AI memory — one that watches what an agent does, maps it into a traceable context graph, and then teaches itself to do that work better overnight. If you use Perplexity’s Computer agent, Brain is the system quietly compounding your productivity every time you log off.
Launched on June 18, 2026, and currently available to Max and Enterprise Max subscribers in Research Preview, Perplexity Brain marks a meaningful shift in how agentic AI systems handle memory — away from user profiling and toward performance improvement.
What Is Perplexity Brain?
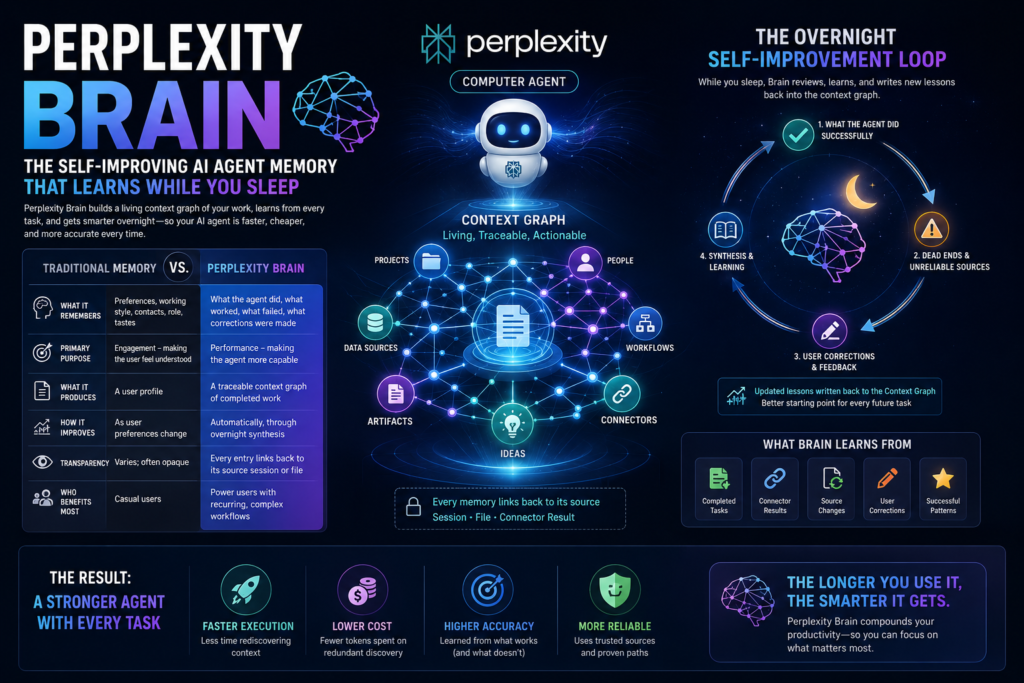
Definition: Perplexity Brain is a self-improving memory system built for Perplexity’s Computer agent. It constructs a living context graph of the work the agent performs, synthesizes that graph at regular intervals (including overnight), and uses what it learns to make future task execution faster, cheaper, and more accurate.
This is not the same as a retrieval-augmented generation (RAG) system bolted onto a chatbot. Brain is tightly coupled to the agent’s action loop. It tracks outputs, learns from corrections, identifies reliable sources, and prunes dead ends — all without any manual input from the user.
In plain terms: every task you run through Computer makes Brain smarter about how to run the next task. The longer you use it, the more efficient it gets.
Traditional AI Memory vs. Perplexity Brain
Most AI products that offer “memory” are building a richer picture of the user. Perplexity is building a richer picture of the work. The distinction sounds subtle but changes everything about what the memory is actually for.
| Dimension | Traditional User Memory | Perplexity Brain (Work Memory) |
|---|---|---|
| What it remembers | Preferences, working style, contacts, role, tastes | What the agent did, what worked, what failed, what corrections were made |
| Primary purpose | Engagement — making the user feel understood | Performance — making the agent more capable |
| What it produces | A user profile | A traceable context graph of completed work |
| How it improves | As user preferences change | Automatically, through overnight synthesis |
| Transparency | Varies; often opaque | Every entry links back to its source session or file |
| Who benefits most | Casual users | Power users with recurring, complex workflows |
Why the Distinction Matters
The question “who is this memory about?” is not pedantic. If memory is about the user, it is optimized to increase perceived personalization. If memory is about the agent’s work, it is optimized to reduce errors, reduce cost, and reduce the number of model calls needed per task. Those are operationally very different goals.
Perplexity’s position is clear: helping the agent get better at the job is the most important purpose of memory. Perplexity Brain is the execution of that philosophy.
How the Context Graph Works
Definition: The context graph is a structured, traceable map of the work Computer has performed. It stores the projects, connectors, artifacts, people, and ideas that appear across a user’s sessions, and organizes them into a form the agent can actively traverse.
The graph is not a flat list of past conversations. It is more like a living wiki — specifically, an LLM wiki that is automatically loaded onto the agent sandbox at the start of each session.
The LLM Wiki Layer
Brain represents the context layer as a set of wiki pages. Each page reflects an element of the user’s world: a project, a data source, a key contact, a workflow step. When Computer begins a new task, it loads the relevant pages and uses them as a starting map — reducing the time it spends rediscovering context that already existed.
The wiki updates incrementally. After each session, and in a larger synthesis pass overnight, Brain reviews completed work, connector results, changes in source documents, and any corrections the user made. It incorporates those signals into new or updated wiki pages before the next session begins.
Traceability — Every Memory Points to a Source
One detail that sets Perplexity Brain apart from opaque memory systems is its traceability. Every entry in the context graph links back to the session, file, or connector result that produced it. If the agent uses a piece of remembered context in a task, you can follow that link to see exactly where the memory came from.
This matters for two reasons. First, it supports debugging. If the agent makes an error that traces back to a stale or incorrect memory, the source can be identified and corrected. Second, it supports trust. Users and enterprise teams managing sensitive workflows need to know what information the agent is drawing on — and why.
The Overnight Self-Improvement Loop
How does Perplexity Brain actually get better over time?
Brain improves through a recursive feedback loop structured around three inputs: what the agent did successfully, what sources led to dead ends, and what corrections the user made.
At set intervals — with the primary cycle running overnight — Brain’s synthesis step processes these inputs and writes updated lessons back into the context graph. The next time the agent encounters a similar task, it starts from a better position: it knows which connectors are reliable, which file paths are relevant, and which approaches previously required correction.
Perplexity frames the current token cost of memory synthesis as an investment. Spending tokens to build better context today means spending fewer tokens on redundant discovery tomorrow. The feedback loop is designed to make each session more efficient than the last.
What Brain Actually Learns From
The synthesis step pulls from four sources:
- Completed sessions — the full record of what the agent did and what it produced
- Connector results — signals about which external data sources delivered useful outputs
- Source document changes — updated files or knowledge bases that may affect prior conclusions
- User corrections — explicit feedback that a result was wrong, a source was a dead end, or a different approach was needed
Each correction is particularly valuable. When a user tells the agent it took the wrong path, Brain encodes that as a lesson: avoid this route in this context. Over time, corrections accumulate into a map of what not to do — which is often more valuable than knowing what to do.
Performance Metrics — What the Early Numbers Show
Perplexity shared first-party performance data from its own internal testing. These are early results from the Research Preview period and have not yet been independently benchmarked.
| Metric | Reported Change | Condition |
|---|---|---|
| Answer correctness | +25% | On tasks Computer has completed before |
| Recall | +16% | Same early-result conditions |
| Inference cost | −13% | On tasks requiring historical context |
Three patterns are worth noting in these numbers. First, the gains are largest on repeat tasks — workflows the agent has seen before. That aligns with the core design: Brain compounds value through repetition, not through a one-time boost. Second, cost reduction accompanies quality improvement, rather than trading off against it. That is the signature of a system that is genuinely reducing redundant work rather than just caching outputs. Third, Perplexity states that results improve the longer someone uses Brain. The implication is that these early numbers represent a floor, not a ceiling.
Who Can Use Perplexity Brain Right Now?
As of the June 2026 launch, Perplexity Brain is available in Research Preview to:
- Perplexity Max subscribers
- Enterprise Max subscribers
It is not yet available on the standard or Pro tiers. The Research Preview designation signals that the feature is functional but still being refined — early adopters should expect iterative changes to how Brain operates, what it surfaces, and how the context graph is displayed.
Access is available through the Computer product at perplexity.ai/computer/memory. Perplexity has not announced a timeline for broader rollout.
Real-World Use Cases for Perplexity Brain
Where does work memory generate the most value? The gains come from tasks with recurring structure — workflows where the agent must re-learn the same context every session without memory, and where that re-learning accumulates significant cost and latency over time.
High-value use cases include:
- Weekly data pipeline audits — Brain remembers which data sources were reliable last cycle and which required manual correction, letting the next audit start from an already-validated map rather than a blank slate.
- Support ticket triage — An agent working through a connector-based ticket queue learns which source documents resolved past tickets, routing future tickets to the right resource with fewer intermediate steps.
- Cross-repository debugging — Brain tracks which files and code paths mattered in previous debugging sessions, allowing the agent to reach the root cause with fewer model calls and less redundant exploration.
- Research synthesis across recurring projects — For analysts or researchers who run similar queries on a regular cadence, Brain builds an understanding of which sources are authoritative for which questions.
- Enterprise workflow automation — Teams using Computer to automate multi-step internal processes benefit from Brain’s ability to learn the organization’s specific connectors, naming conventions, and correction patterns.
In every case, the mechanism is the same: history replaces re-discovery, and the savings compound.
Open Questions and Honest Limitations
Perplexity Brain is technically compelling, but it is early-stage, and a fair assessment requires naming what is not yet resolved.
Limitations worth watching:
- First-party metrics only. The +25% correctness and −13% cost figures come from Perplexity’s own testing. Independent benchmarks on real-world, diverse workflows do not yet exist. External validation is the next meaningful test.
- Overnight update cadence. Because the primary synthesis cycle runs overnight, improvements are not instantaneous. A correction made in the morning may not be fully incorporated until the following day. For fast-moving workflows, this lag matters.
- Limited availability. Brain is restricted to Max and Enterprise Max tiers in Research Preview. Teams on standard plans cannot evaluate it yet, limiting the range of real-world feedback Perplexity can collect.
- Data governance questions. Persisting a detailed context graph of an agent’s work — including connector results, document contents, and correction history — raises legitimate questions about data retention, access controls, and compliance. Enterprise teams will need clear answers before deploying Brain on sensitive workflows.
- Graph staleness. If a source document changes significantly, Brain’s memory about that source may lag behind reality until the next synthesis cycle catches up. For domains where source data changes rapidly, this is a meaningful gap.
None of these limitations disqualify the system. They are the natural profile of a well-designed feature in early preview — strong conceptual foundation, promising early metrics, real-world validation still ahead.
Why Perplexity Brain Signals a Shift in Agentic AI
The release of Perplexity Brain is worth paying attention to beyond the specific performance numbers, because it articulates a design philosophy that is likely to spread.
Most memory features added to AI products over the last two years have been user-facing: remember my preferences, learn my writing style, store my contacts. These features improve the experience of using an agent, but they do not make the agent more capable at doing work.
Perplexity Brain makes a different bet. It says that the most valuable thing memory can do is reduce the cost and increase the accuracy of future task execution. The target is not the user’s comfort — it is the agent’s job performance. And it operationalizes this bet with a concrete mechanism: a context graph, a synthesis loop, and a set of measurable outcomes (correctness, recall, cost).
If those outcomes hold at scale and across diverse workflows, the implication is significant for enterprise agentic AI adoption. The biggest barrier to deploying agents on high-stakes recurring tasks is trust — specifically, the worry that the agent will make the same mistake twice. A memory system that explicitly learns from corrections and encodes dead ends as avoidable paths directly addresses that concern.
Perplexity Brain does not solve all of the trust problems in agentic AI. But it frames memory as a correctness and reliability tool rather than a personalization feature, and that reframing is one the broader industry is likely to follow.
Frequently Asked Questions
What is Perplexity Brain, in one sentence? Perplexity Brain is a self-improving memory system for the Perplexity Computer agent that builds a traceable context graph of completed work and synthesizes it overnight to make future tasks faster, cheaper, and more accurate.
How is Perplexity Brain different from other AI memory systems? Most AI memory systems store information about the user — preferences, style, contacts. Perplexity Brain stores information about the agent’s work — what it did, what worked, what failed, and what corrections were made. The purpose is agent performance, not user personalization.
Does Perplexity Brain improve in real time? No. The primary synthesis cycle runs overnight, meaning corrections and new session data are incorporated on a scheduled cadence rather than instantly. Real-time reflection is not part of the current design.
Is Perplexity Brain available to all Perplexity users? Not yet. As of launch, Perplexity Brain is available in Research Preview to Max and Enterprise Max subscribers only.
What does “traceable memory” mean in this context? Every entry in Brain’s context graph links back to the session, file, or connector result that generated it. If the agent draws on a memory to complete a task, the source of that memory can be identified — supporting both debugging and audit.
What are the reported performance gains from Perplexity Brain? Perplexity reports a 25% improvement in answer correctness on repeat tasks, a 16% improvement in recall, and a 13% reduction in inference cost on tasks requiring historical context. These are early, first-party figures from the Research Preview period.
Conclusion
Perplexity Brain reframes what AI agent memory is for. By shifting the target from user profiling to work performance, it opens a path toward agents that genuinely improve through use — not just agents that feel more personalized. The context graph, the overnight synthesis loop, and the traceability of every memory entry are well-designed components of a coherent system.
The open questions are real: first-party metrics need independent validation, overnight update cadence creates lag, and data governance for enterprise workloads still needs to be addressed. But the architecture is sound, and the early numbers are directionally strong.
For teams running high-stakes, recurring workflows through Perplexity Computer, Brain is worth evaluating now. For the broader agentic AI industry, it is worth watching closely — because the bet it makes about what memory is for may turn out to be the right one.