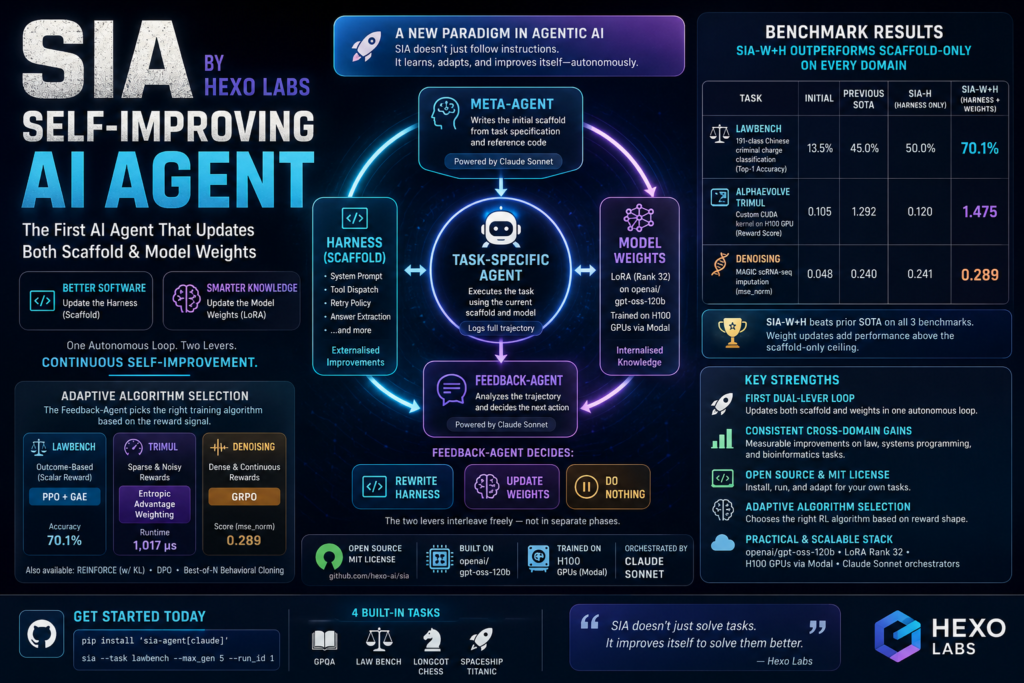
Most AI agents stop learning the moment a human stops tuning them. SIA — the open-source self-improving AI agent released by Hexo Labs in May 2026 — changes that by editing both its own operational scaffold and its model weights inside a single autonomous loop, consistently outperforming scaffold-only approaches across every benchmark it was tested on.
If you’re building or evaluating autonomous AI systems, this framework represents a meaningful architectural shift worth understanding in detail.
What Is a Self-Improving AI Agent?
Definition: A self-improving AI agent is an autonomous system capable of modifying its own code, configuration, or model parameters based on feedback from its own task performance — without requiring external human intervention to initiate each update.
Most current systems improve along only one axis. A prompt-engineering pipeline rewrites system instructions but leaves the model weights frozen. A test-time training pipeline fine-tunes weights but treats the scaffold as static. A genuine self-improving AI agent can move both levers.
SIA is the first publicly documented system to do this inside one closed feedback loop. After each task run, a dedicated Feedback-Agent reads the full execution trajectory and decides whether to rewrite the scaffold, trigger a weight update via LoRA, or both — in whatever sequence the reward signal suggests is most useful.
How SIA Works: The Two-Lever Architecture
SIA divides a task-specific agent into two separable components that can each be updated independently.
The Harness (Scaffold)
The harness is the software envelope around the model: the system prompt, tool-dispatch logic, retry policy, and answer-extraction code. In most agentic frameworks, this is where all the engineering effort goes. A Meta-Agent writes the initial harness from a task specification and any reference code provided at setup time.
Harness updates are “externalised” improvements. They make the agent a better software engineer — tighter parsers, smarter retry logic, better tool selection. The base model itself is unchanged.
The Model Weights
The model weights are the second lever. SIA uses openai/gpt-oss-120b as its base, with weight updates applied through LoRA (Low-Rank Adaptation) at rank 32, running on H100 GPUs via Modal. These updates “internalise” knowledge — they change what the model actually knows, not just how it’s instructed to behave.
This is the critical distinction. Some domain knowledge is effectively unreachable through prompting alone. The integer-rounding step that lifted SIA’s single-cell RNA denoising score is a clean example: no amount of scaffold rewriting surfaced it. Weight updates did.
The Feedback-Agent’s Decision Loop
Three LLM components drive the loop:
- Meta-Agent — Writes the initial scaffold from the task spec and reference code. Runs on Claude Sonnet.
- Task-Specific Agent — Executes the task and logs every step of its trajectory.
- Feedback-Agent — Reads the full trajectory and picks the next action: rewrite the harness, trigger a LoRA weight update, or do nothing if performance is already optimal. Also runs on Claude Sonnet.
After each run, the Feedback-Agent’s choice determines which lever moves. The two levers interleave freely — they are not locked into sequential phases.
This design is what distinguishes a true self-improving AI agent from a system that only automates one side of the improvement process.
Benchmark Results: What the Numbers Actually Show
Hexo Labs tested SIA across three deliberately different domains to avoid cherry-picking a task where one specific architecture would obviously win. The results held consistently across all three.
| Task | Initial | Previous SOTA | SIA-H (Harness Only) | SIA-W+H (Harness + Weights) |
|---|---|---|---|---|
| LawBench — 191-class Chinese criminal charge classification (top-1 accuracy) | 13.5% | 45.0% | 50.0% | 70.1% |
| AlphaEvolve TriMul — custom CUDA kernel on H100 GPU (reward score) | 0.105 | 1.292 | 0.120 | 1.475 |
| Denoising — MAGIC scRNA-seq imputation (mse_norm) | 0.048 | 0.240 | 0.241 | 0.289 |
Reading the table: SIA-H is the scaffold-only baseline — the performance ceiling of iterating purely on the harness. SIA-W+H adds weight updates on top. The gap between the two columns is the contribution that model weight updates make beyond what software engineering alone can achieve.
On LawBench, the Feedback-Agent built a TF-IDF plus LinearSVC classification pipeline through harness iteration and plateaued at 50.0%. PPO-based weight updates then pushed accuracy to 70.1% — a 20.1 percentage-point gain over the scaffold-only peak, and a 25.1-point margin over the previous state of the art.
On TriMul, scaffold edits reached a modest 1.14x speedup over baseline. Weight updates then drove runtime from 12,483 microseconds down to 1,017 microseconds — a 91.9% reduction. One honest caveat: Claude Code reached 1.50x on TriMul unaided, beating SIA-H’s 1.14x. SIA-W+H still led overall at 14.02x.
On denoising, the harness settled on 0.241 mse_norm through hyperparameter sweeps. The first weight-update checkpoint discovered a two-line rounding step that lifted the score to 0.289 — a change no scaffold rewrite had found, because it required the model to “know” something about non-negative integer constraints in count data.
SIA vs. Prior Approaches: What Makes This Different
To understand the significance of this architecture, it helps to compare it against the two dominant prior paradigms for agent improvement.
| Dimension | Scaffold-Only (e.g., prompt engineering, agentic frameworks) | Test-Time Training (e.g., RL fine-tuning pipelines) | SIA (Harness + Weights) |
|---|---|---|---|
| What changes | System prompt, tools, retry logic | Model parameters | Both, in one loop |
| What stays fixed | Model weights | Scaffold | Nothing — both are updatable |
| Human involvement | Required to initiate each round | Required to design the RL setup | Not required after initial task spec |
| Knowledge type improved | Procedural / instructed | Internalised / parametric | Both |
| Open source | Varies | Rarely | Yes (MIT license) |
| Benchmark SOTA beaten | Sometimes | Sometimes | Yes, on all 3 tested domains |
The core innovation is not a better scaffold engine or a better RL recipe in isolation — it’s the integration of both into one feedback loop where a third model (the Feedback-Agent) decides which lever to pull based on the current reward signal.
How the Feedback-Agent Selects Its Training Algorithm
Question: Does SIA use the same RL algorithm for every task?
No. One of the more technically interesting aspects of SIA as a self-improving AI agent is that the Feedback-Agent selects its training algorithm dynamically, based on the shape of the reward signal it observes. This is not a fixed schedule.
Here is how algorithm selection played out across the three benchmark tasks:
- LawBench — A clean outcome-based scalar reward (correct charge classification or not). The Feedback-Agent selected PPO with Generalized Advantage Estimation (GAE). Accuracy reached 70.1%.
- TriMul — Most kernel compilations failed, producing sparse and noisy reward signals. The Feedback-Agent selected entropic advantage weighting, which up-weights rare high-reward rollouts rather than averaging across mostly-failed attempts. Final runtime hit 1,017 microseconds.
- Denoising — A dense, continuous reward signal from the MSE metric. The Feedback-Agent selected GRPO (Group Relative Policy Optimization), which eliminates the value network entirely. Score rose to 0.289.
The full algorithm library available to the Feedback-Agent also includes REINFORCE with KL-to-base regularization, Direct Preference Optimization (DPO), and best-of-N behavioural cloning. Each maps to a different reward shape and failure profile.
This adaptive algorithm selection is itself a form of meta-level self-improvement — the self-improving AI agent is not just updating its task performance, it is also adapting how it updates itself.
Key Strengths and Honest Limitations
Strengths
- First dual-lever loop: SIA is the first system in the public literature to edit both scaffold and weights inside a single autonomous self-improvement loop, with no human-initiated intervention required between iterations.
- Consistent cross-domain gains: Weight updates added measurable performance above the scaffold-only ceiling on all three tested domains — law, systems programming, and bioinformatics — suggesting the approach generalises rather than overfitting to one task type.
- Open source under MIT: The framework ships as
sia-agent(installable via pip), with four bundled benchmark tasks:gpqa,lawbench,longcot-chess, andspaceship-titanic. - Adaptive algorithm selection: The Feedback-Agent conditions its training algorithm choice on the observed reward signal, rather than running a fixed RL recipe regardless of task structure.
- Practical deployment stack: Built on
openai/gpt-oss-120bwith LoRA rank 32, training on H100 GPUs via Modal. The Meta-Agent and Feedback-Agent both run on Claude Sonnet, keeping orchestration costs decoupled from the heavy training runs.
Limitations to Keep in View
- Three tasks is a small evaluation set. Broader algorithm-selection results across diverse domains are deferred in the paper. The generalisability of the approach beyond these three domains is an open empirical question.
- Both levers optimise the same fixed verifier. When the harness and the weights are both optimised against an identical reward signal, there is a risk of coupled co-evolutionary Goodhart effects — where the joint system gets very good at satisfying the verifier without improving on the underlying task.
- Fixed-point fragility. The authors themselves warn that a joint fixed point reached through this loop may appear strong on the benchmark verifier but remain fragile under perturbation or distribution shift.
- A separate “350x superintelligence” claim that appeared in some launch coverage does not appear anywhere in the paper itself. Treat it as marketing language, not a technical claim.
How to Run SIA Yourself
SIA is open source under an MIT license at github.com/hexo-ai/sia. Getting started requires an Anthropic API key (for the Meta-Agent and Feedback-Agent) and access to an H100 GPU environment through Modal for weight update runs.
bash
# Install the Claude backend
pip install 'sia-agent[claude]'
export ANTHROPIC_API_KEY="your-key-here"
# Run 5 self-improvement generations on the LawBench task
sia --task lawbench --max_gen 5 --run_id 1The four bundled tasks — gpqa, lawbench, longcot-chess, and spaceship-titanic — cover a deliberate variety of domains and reward structures, which makes them useful for understanding how the self-improving AI agent behaves under different feedback conditions before you adapt it to your own task.
For teams that want to add a custom task, the framework exposes a task specification interface where you provide a description, reference code if available, and a verifier function that returns a scalar reward.
Why This Matters for the Future of Agentic AI
The field of agentic AI has been moving along two parallel tracks that have rarely intersected. On one track, researchers and engineers iterate on scaffolds: better prompts, better tool use, better orchestration. On the other, ML researchers iterate on weights: better RL recipes, better fine-tuning pipelines, better reward shaping.
SIA’s contribution is architectural: it proposes that a self-improving AI agent should not be constrained to one track. The Feedback-Agent’s ability to look at an execution trajectory and decide whether the problem is a software problem (fix the harness) or a knowledge problem (update the weights) mirrors how a thoughtful human engineer would diagnose a struggling system.
The benchmark results suggest this is not a marginal improvement. On LawBench, the gap between harness-only iteration and the combined approach was 20 percentage points. On TriMul, it was the difference between a modest speedup and a 14x gain. On denoising, it was a two-line insight that no amount of scaffold rewriting could surface.
What SIA still needs is a wider evaluation surface. Three tasks is a proof of concept. The harder questions — how the approach scales to longer task horizons, how the Feedback-Agent performs when the reward signal is deceptive or adversarially shaped, and whether the joint optimisation introduces failure modes that only emerge after many iterations — remain open.
But as an open-source framework that any team can install, run, and adapt today, SIA gives the research community something concrete to interrogate. That alone makes it worth close attention.
Frequently Asked Questions
What is SIA in AI? SIA stands for Self-Improving AI. It is an open-source agentic framework released by Hexo Labs that enables a self-improving AI agent to update both its operational scaffold (the system prompt, tools, and retry logic) and its model weights (via LoRA fine-tuning) inside a single autonomous feedback loop.
What is the difference between SIA-H and SIA-W+H? SIA-H uses harness (scaffold) updates only — the model weights stay fixed. SIA-W+H adds LoRA weight updates on top of harness iteration. Across all three benchmarks tested, SIA-W+H outperformed SIA-H, with the largest gap appearing on LawBench (50.0% vs. 70.1%).
What base model does SIA use? SIA uses openai/gpt-oss-120b as its base model. Weight updates are applied through LoRA at rank 32. The Meta-Agent and Feedback-Agent components both run on Claude Sonnet.
Is SIA open source? Yes. SIA is released under an MIT license at github.com/hexo-ai/sia and is installable as sia-agent via pip.
What tasks are included with SIA? Four benchmark tasks ship with the framework: gpqa, lawbench, longcot-chess, and spaceship-titanic.
Conclusion
The emergence of the self-improving AI agent marks a significant turning point in the evolution of artificial intelligence. For years, the AI industry has relied on two largely separate approaches to improvement. One camp focused on refining prompts, scaffolds, workflows, and tool orchestration, while another concentrated on model training, reinforcement learning, and weight optimization. SIA from Hexo Labs demonstrates that the future may belong to systems that combine both approaches into a unified architecture. By enabling a self-improving AI agent to modify both its operational scaffold and underlying model weights, SIA introduces a new framework for autonomous learning that goes beyond traditional agent design.
What makes this development particularly important is that a self-improving AI agent is not limited to improving only how it executes tasks. Instead, it can determine whether a problem requires better instructions, improved tooling, enhanced workflows, or deeper knowledge encoded directly into the model. This dual-lever approach allows a self-improving AI agent to evolve in ways that previous systems could not. Rather than depending entirely on prompt engineering or entirely on model training, SIA intelligently combines both methods to maximize performance.
The benchmark results presented by Hexo Labs provide compelling evidence that the self-improving AI agent concept has practical value. Across legal classification, CUDA kernel optimization, and bioinformatics denoising tasks, the combined scaffold-and-weight approach consistently outperformed scaffold-only systems. These gains were not small incremental improvements. In multiple cases, the self-improving AI agent surpassed previous state-of-the-art results while demonstrating the ability to identify solutions that could not be discovered through scaffold optimization alone. This suggests that future AI systems may increasingly rely on integrated learning architectures rather than isolated optimization strategies.
Another reason the self-improving AI agent deserves attention is its adaptive learning process. The Feedback-Agent does not simply trigger a predefined training procedure. Instead, it analyzes reward signals and selects the most appropriate optimization method for the task at hand. This capability allows the self-improving AI agent to adjust its own improvement strategy based on the characteristics of the environment. Such meta-level decision-making represents an important step toward more autonomous and flexible AI systems capable of handling a wider range of real-world challenges.
The open-source nature of SIA also increases its significance. Because the self-improving AI agent framework is released under an MIT license, researchers, developers, startups, and enterprises can experiment with the architecture without being restricted to proprietary platforms. Open access encourages independent validation, further benchmarking, and the discovery of new applications. As more organizations test and refine the self-improving AI agent paradigm, the broader AI community will gain valuable insights into its strengths, limitations, and scalability.
At the same time, it is important to maintain realistic expectations. The current evaluation of the self-improving AI agent is based on only three benchmark domains, which means broader validation is still needed. Questions regarding robustness, long-term stability, reward hacking, and performance under distribution shifts remain open. The possibility of co-evolutionary optimization against a fixed verifier is another area that researchers must investigate carefully. These limitations do not diminish the achievement, but they do highlight the need for continued testing and rigorous analysis before the self-improving AI agent concept can be considered universally proven.
Looking ahead, the implications are substantial. If future versions of a self-improving AI agent can safely operate across longer task horizons, manage complex workflows, and adapt to changing objectives, they could transform how AI systems are developed and maintained. Instead of requiring constant human intervention, a self-improving AI agent could continuously refine its capabilities, identify weaknesses, and implement improvements autonomously. This vision aligns closely with the long-term goals of agentic AI research and may ultimately redefine what it means for an AI system to learn.
In the end, SIA should be viewed as more than just another AI framework. It is an important experiment that challenges conventional assumptions about how intelligent systems improve over time. Whether the self-improving AI agent becomes the dominant architecture of the next generation remains to be seen, but the early evidence suggests it has the potential to influence the direction of agentic AI research for years to come. For developers, researchers, and organizations exploring advanced autonomous systems, understanding the principles behind the self-improving AI agent is likely to become increasingly valuable as the technology continues to mature throughout 2026 and beyond. SIA AI Framework