Agent memory is the infrastructure that transforms a stateless LLM into a system that learns, plans, and acts over time. If you are building AI agents and wondering why they forget context, repeat mistakes, or lose track of long-horizon goals, the answer is almost always a missing or mismatched memory layer.
This guide breaks down all seven types of agent memory — what each one stores, where it lives, when to use it, and how to layer them together into a production-grade system. Whether you are building a personal assistant, a research agent, or an autonomous workflow engine, this is the architectural map you need.
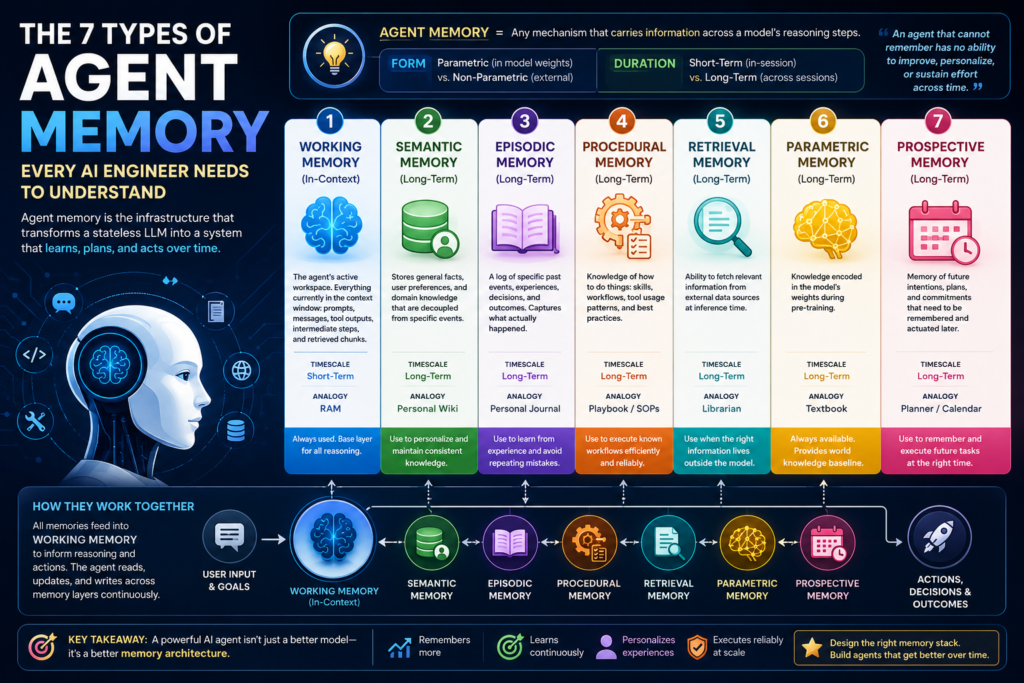
What Is Agent Memory?
Definition: Agent memory is any mechanism that carries information across a model’s reasoning steps — whether that information lives inside the active context window, in an external database, or baked into the model’s weights.
Expansion: Most large language models are stateless by design. Each API call starts from a blank slate. That behavior works fine for a single Q&A turn, but the moment your system plans across multiple steps, calls tools, runs in the background, or needs to remember a user’s preferences, statelessness becomes a hard architectural limit. Agent memory is the layer that breaks that limit.
Memory for AI agents varies along two axes:
- Form: Parametric (encoded in model weights) vs. non-parametric (stored as text, embeddings, or structured records outside the model).
- Duration: Short-term (available only during the current inference or session) vs. long-term (persists across sessions and restarts).
All seven types of agent memory map onto those two axes.
Why LLMs Are Stateless — and Why That Breaks Agents
Question: Why does statelessness matter so much for agentic systems?
Direct answer: An agent that cannot remember has no ability to improve, personalize, or sustain effort across time. It re-reasons every step from zero, ignores prior failures, and loses user context the moment a session ends.
Consider what a multi-step agent actually needs to do:
- Track the progress of a task in flight (working memory)
- Recall facts about the user or domain across sessions (semantic memory)
- Learn from prior task outcomes (episodic memory)
- Execute known workflows without re-planning (procedural memory)
- Pull in relevant external documents at inference time (retrieval memory)
- Access world knowledge encoded during training (parametric memory)
- Remember future commitments it made earlier in the task (prospective memory)
Each of those needs corresponds to exactly one type of agent memory. Skip any of them and the agent loses a specific capability that cannot be recovered another way.
The 7 Types of Agent Memory Explained
1. Working Memory (In-Context)
What it is: Everything currently visible inside the model’s context window — the system prompt, conversation history, tool call outputs, intermediate reasoning steps, and retrieved chunks. This is the agent’s active workspace.
Analogy: RAM. Fast, essential, and finite. When the context fills up, something has to be evicted. That forces every other memory type to compete for this scarce real estate.
Timescale: Short-term. It resets with every new session or API call.
When to use it: Always. Every agent has working memory by default — it is the base layer. Every other type ultimately gets loaded into working memory to be reasoned over. The design challenge is managing what gets pulled in and when, so that the context remains focused and relevant.
Key constraint: Context windows are growing, but they are never unlimited. An agent handling a long project cannot keep the entire history in context. This is what motivates external long-term memory.
2. Semantic Memory (Long-Term)
What it is: A persistent store of facts, user preferences, and domain knowledge that is decoupled from the specific event in which it was learned. Entries like “this user prefers Python,” “the company uses a three-tier review process,” or “the client is in the healthcare sector” all belong here.
Analogy: A well-organized personal wiki. The agent consults it when context is relevant, regardless of when the fact was first recorded.
Timescale: Long-term. Semantic memory survives across sessions indefinitely.
When to use it: Build semantic memory the moment your agent is expected to personalize its behavior across multiple sessions. This is the first long-term memory layer most production agents need.
Implementation: Typically a vector database or structured profile schema. The agent writes new facts as they emerge, retrieves them by relevance at inference time, and loads them into working memory as needed.(AI Agent MemoryTypes of Agent MemoryAI Agent ArchitectureMemory Systems in AI)
3. Episodic Memory (Long-Term)
What it is: A log of specific past events — full conversations, task runs, decisions made, and their outcomes. Where semantic memory stores what is generally true, episodic memory records what actually happened: what the agent tried, what worked, and what failed.
Analogy: A personal journal that the agent reviews before each new task to understand its own track record.
Timescale: Long-term.
When to use it: When your agent needs to improve from experience rather than repeating the same mistakes. Research systems like Reflexion and ExpeL operationalize this: they write verbal post-mortems after each task and store conclusions that guide future runs.
Implementation: A vector database combined with structured event logs. Each entry includes a timestamp, a description of the event, and a tagged outcome. The agent retrieves relevant past episodes before attempting a similar task.
4. Procedural Memory (Long-Term)
What it is: The agent’s encoded knowledge of how to do things — skills, tool usage patterns, multi-step workflows, and behavioral rules. A support agent handling its hundredth password reset does not re-reason the full procedure. It executes a stored skill.
Analogy: Muscle memory. The agent has internalized a workflow to the point where it executes rather than deliberates.
Timescale: Long-term.
When to use it: When the agent repeatedly performs the same class of task. Encoding the workflow as procedural memory removes unnecessary reasoning overhead, reduces errors, and makes behavior more consistent.
Implementation: Procedural memory lives either in the system prompt (as explicit instructions and workflow templates) or in fine-tuned model weights (when the skill needs to be deeply internalized). Prompt-based procedural memory is easier to update; weight-based is more robust under distribution shift.
5. External / Retrieval Memory (Short-Term + Long-Term)
What it is: Knowledge stored outside the model in a vector database and pulled into the context window at inference time using similarity search. This is retrieval-augmented generation (RAG) applied to agent history, internal documents, or external knowledge bases.
Analogy: A vast filing cabinet the agent searches before answering, surfacing exactly the pages most relevant to the current question.
Timescale: The store itself is long-term; the retrieved chunks are loaded into working memory for the duration of a single inference call (short-term).
When to use it: Whenever your agent needs to answer questions grounded in a large body of text — product documentation, legal filings, research papers, historical conversation logs — that cannot fit in the active context window.
Key constraint: Retrieval quality becomes the bottleneck fast. The agent can only reason over what gets retrieved. Poor embedding quality, stale indexes, or miscalibrated similarity thresholds produce confident but wrong answers. Invest in retrieval evaluation early.
6. Parametric Memory (Long-Term)
What it is: Knowledge baked directly into the model’s weights during pre-training or fine-tuning. This includes language understanding, general world knowledge, reasoning patterns, and domain expertise. The model does not look anything up — it generates from learned associations.
Analogy: A human expert’s deep background knowledge. It was assembled over years of study and is now inseparable from how the expert thinks.
Timescale: Long-term, but static. Parametric memory is frozen at training time and cannot be updated without retraining.
When to use it: Parametric memory is always present. It is the base model itself. The relevant design decision is when to extend it through fine-tuning — for example, when an agent must embody proprietary domain knowledge that cannot be served adequately through retrieval.
Key tradeoff: Unlike retrieval memory, parametric knowledge cannot be audited or updated on the fly. A model fine-tuned on outdated legal regulations will confidently cite the wrong rules. Prefer retrieval for time-sensitive or frequently-changing knowledge.(AI Agent MemoryTypes of Agent MemoryAI Agent ArchitectureMemory Systems in AI)
7. Prospective Memory (Short-Term + Long-Term)
What it is: The agent’s capacity to hold future intentions and scheduled goals — things it has committed to doing but has not yet executed. Without this layer, an agent forgets its own plans the moment they fall out of the active context window.
Analogy: A calendar reminder system for the agent’s own commitments. “Send the Friday summary.” “Follow up with the client on Tuesday.” “Resume the analysis after the data pipeline finishes.”
Timescale: Can be short-term (a pending step in the current task) or long-term (a goal scheduled for next week).
When to use it: Any agent running multi-step tasks or operating across long time horizons requires prospective memory. Without it, the agent drops the thread the moment the task exceeds the context window or the session ends.
Implementation: A task queue, a structured scheduler, or a dedicated state store that the agent writes to when it makes a commitment and reads from when it resumes execution.
Comparison Table — All 7 Types of Agent Memory at a Glance
| Memory Type | Timescale | Where It Lives | What It Stores | Common Implementation |
|---|---|---|---|---|
| Working / In-Context | Short-term | Context window | Prompt, messages, tool outputs, reasoning | Native to the LLM |
| Semantic | Long-term | External store | Facts, preferences, domain knowledge | Vector DB or profile schema |
| Episodic | Long-term | External store | Past events, task runs, outcomes | Vector DB + structured event log |
| Procedural | Long-term | Prompt or weights | Skills, workflows, behavioral rules | System prompt or fine-tuning |
| External / Retrieval | Short + Long | Vector database | Documents, history chunks | RAG pipeline |
| Parametric | Long-term | Model weights | World knowledge, language, reasoning | Pre-training or fine-tuning |
| Prospective | Short + Long | State store | Future intentions, scheduled goals | Task queue or scheduler |
Which Agent Memory Type Solves Which Problem?
Each type of agent memory answers a specific, concrete product need. Use this mapping to diagnose your agent’s current gaps:
- “The agent forgets what we discussed earlier in the conversation.” → Fix: ensure your working memory (context window) includes sufficient conversation history, and trim irrelevant content to make room.
- “The agent doesn’t remember my preferences from last week.” → Fix: add semantic memory. Write user facts to a persistent store and retrieve them at the start of each session.
- “The agent makes the same mistakes repeatedly.” → Fix: add episodic memory. Log task outcomes and retrieve relevant past failures before each new run.
- “The agent takes too long to reason through standard workflows.” → Fix: encode those workflows as procedural memory in the system prompt or fine-tune the model on them.
- “The agent gives answers that contradict our internal documentation.” → Fix: add retrieval memory. Embed your docs and require the agent to ground its answers in retrieved text.
- “The agent doesn’t know our industry-specific terminology.” → Fix: extend parametric memory through domain fine-tuning, or load a curated glossary via retrieval.
- “The agent forgets to follow up on things it promised to do.” → Fix: implement prospective memory using a task queue that persists across sessions.
How All 7 Types Work Together in One Agent
The cleanest way to understand why all seven types of agent memory matter is to watch them interact in a single system.
Consider an autonomous market-analysis agent assigned to produce a weekly competitive intelligence report.
Parametric memory supplies the base reasoning capacity and language fluency — the model’s foundational understanding of markets, strategy, and writing.
Retrieval memory pulls current market data, competitor filings, and recent news articles from a vector store at query time, grounding the analysis in up-to-date facts.
Semantic memory provides durable context about the client: their preferred report format, the sectors they monitor, and the competitors they care most about.
Episodic memory recalls which sources proved reliable in prior reports and which analytical angles the client found most valuable last month.
Procedural memory drives the report’s section order — market sizing first, then competitive landscape, then risk factors — executing a learned editorial workflow rather than re-deriving the structure from scratch.
Prospective memory schedules the follow-up draft for next Friday and sets a reminder to verify the competitor’s earnings release before publishing.
Working memory assembles all of the above into the active context for each inference call, giving the model everything it needs to reason and write.
Remove any one layer and a specific capability disappears. The agent becomes slower, less accurate, less personalized, or less reliable. Each type handles a job the others cannot substitute for.
(AI Agent MemoryTypes of Agent MemoryAI Agent ArchitectureMemory Systems in AI)
A Practical Build Order: Start Simple, Add Only What You Need
The biggest mistake engineers make with agent memory is trying to implement all seven types at once. Complexity compounds fast, and most early-stage agents do not need the full stack. Here is a sequencing that holds up in practice:
- Start with working memory. It ships with the model. Treat context management — what goes in, in what order, at what length — as your first engineering discipline. Most simple agents need nothing more than this.
- Add semantic memory when users expect personalization across sessions. This is the single most common reason agents feel generic. Write key facts about the user as they emerge; retrieve them at the start of each session.
- Add retrieval memory when the agent needs to answer questions grounded in a large document corpus. Build your RAG pipeline, invest in chunking and embedding quality, and evaluate retrieval precision before optimizing generation.
- Add episodic memory when the agent must improve from experience. This is the layer that makes an agent get better over time rather than plateauing at its initial capability level.
- Add procedural memory when repeated workflows create unnecessary reasoning overhead. Encode proven sequences in the system prompt first; graduate to fine-tuning only when prompt-based procedural memory is insufficient.
- Add prospective memory when the agent runs tasks that span multiple sessions or long time horizons. A task queue is usually sufficient to start; graduate to a full scheduler as complexity grows.
- Treat parametric memory as a baseline, not a destination. The base model you choose is your starting parametric layer. Fine-tune it only when retrieval and prompt-based approaches consistently fail to meet accuracy requirements.
Frequently Asked Questions
Q: What is the difference between working memory and retrieval memory in an AI agent?
Working memory is what the model can currently see — the active context window. Retrieval memory is an external database that the agent searches to pull relevant information into that context window. Working memory is immediate and implicit; retrieval memory requires an explicit lookup step and a vector similarity search. The two work together: retrieval populates working memory with the right content, and working memory is where reasoning actually happens.
Q: Do all AI agents need all seven types of agent memory?
No. A simple single-session agent may only need working memory. A coding assistant that helps you within one file does not need long-term semantic or episodic memory. Add memory layers incrementally, only when a real product requirement justifies the engineering complexity. The build order above is a reliable guide.
Q: What is the CoALA framework?
CoALA (Cognitive Architectures for Language Agents) is a Princeton research framework (arXiv:2309.02427) that provides a unified taxonomy for classifying agent memory types. It maps working, semantic, episodic, and procedural memory — drawn from cognitive science — onto LLM-based agent systems. It is the foundational reference for the seven-type model described in this post.
Q: How does RAG relate to agent memory?
Retrieval-augmented generation (RAG) is the most common implementation of external retrieval memory. It involves embedding a document corpus in a vector database and retrieving relevant chunks at inference time. When applied to an agent’s own history — past conversations, prior task outputs — rather than external documents, it becomes episodic retrieval. RAG is the mechanism; retrieval memory is the architectural concept.
Q: Can parametric memory replace retrieval memory?
Rarely in practice. Parametric memory is frozen at training time, so it cannot reflect events, policies, or data that postdate the training cutoff. It also cannot be audited or corrected without retraining. Retrieval memory, by contrast, can be updated instantly by modifying the vector store. For any knowledge that changes over time or that must be verifiable and correctable, retrieval memory is the right choice. Parametric memory excels at stable reasoning patterns and general world knowledge.
Key Takeaways
Agent memory is not one thing — it is a stack of seven distinct mechanisms, each solving a problem the others cannot. Working memory is the base. Semantic and retrieval memory handle persistence and grounding. Episodic and procedural memory enable learning and efficiency. Prospective memory sustains long-horizon goals. Parametric memory is the model’s foundational intelligence.
Build incrementally. Start with working memory, add semantic memory when sessions need to feel continuous, layer retrieval when grounding matters, and introduce the remaining types only as your agent’s use case demands. A well-designed agent memory stack is what separates a capable AI assistant from one that merely answers questions.